

- 1.89 MB
- 2022-08-13 发布


- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
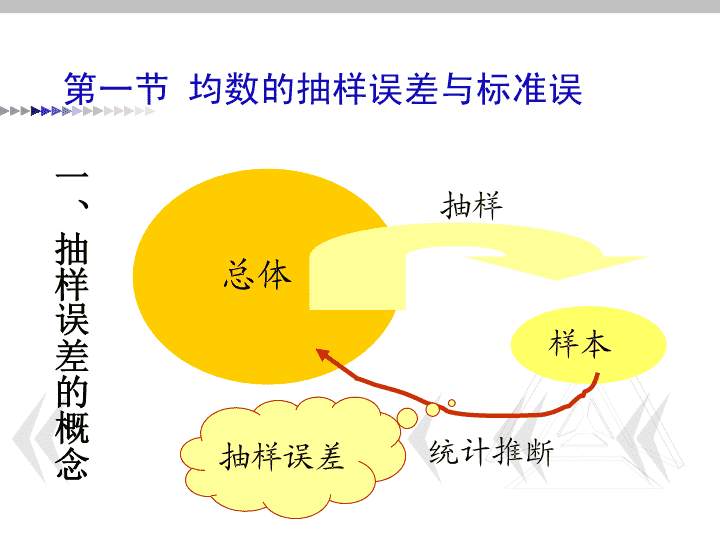
卫生(医学)统计学普通高等教育“十一五”国家级规划教材第四章总体均数的估计和假设检验\n第一节均数的抽样误差与标准误总体样本统计推断抽样抽样误差一、抽样误差的概念\n由于总体中存在个体变异,(所以)由抽样得到的样本指标与总体指标之间存在差异,这种差异称抽样误差。在抽样研究中,抽样误差是不可避免的,但其大小可以控制和估计的。\n二、中心极限定理1、在正态总体中,随机抽取例数为n的样本,样本均数服从正态分布;2、在偏态总体中随机抽样,当n足够大时(n>30),也近似正态分布;3、从均数为μ,标准差为σ的正态或偏态总体中,抽取例数为n的样本,样本均数的均数仍为μ,标准差。\n三、标准误意义及其计算方法1、标准误意义:说明抽样误差大小的指标。均数抽样误差用表示;率的抽样误差用σp表示。\n2、计算公式:........(理论值)........(估计值)\n随着nS稳定0均数的标准误与标准差成正比,与样本例数n的平方根成反比。因此,减少抽样误差最有效的办法:增加样本例数\n例4.1已知n=144,=5.38×1012/L,S=0.44×1012/L求其标准误。(×1012/L)\n3、标准误的应用(1)反映抽样误差大小:标准误越大,抽样误差越大;(2)反映均数的可靠性:越大,样本均数的抽样误差越大,(用样本均数推算总体均数的)可靠性差;反之,越小,均数抽样误差越小,(用样本均数推算总体均数的)可靠性好。(3)用于进行假设检验(见下节)\n标准差,标准误有何区别和联系?标准差和标准误都是变异指标,但它们之间有区别,也有联系。区别:①概念不同:标准差是描述观察值(个体值)之间的变异程度,S越小,均数的代表性越好;标准误是描述样本均数的抽样误差,越小,均数的可靠性越高;\n③与样本含量的关系不同:当样本含量n足够大时,标准差趋向稳定;而标准误随n的增大而减小,甚至趋于0。联系:标准差、标准误均为变异指标,当样本含量不变时,标准误与标准差成正比。②用途不同:标准差与均数结合估计参考值范围,计算变异系数,计算标准误等。标准误用于估计参数的可信区间,进行假设检验等。\n第二节t分布一、t分布的概念t值分布称t分布u变换:u值的分布称u分布\n二、t分布特征:1、以0为中心,左右对称的单峰分布;2、t分布的形态与自由度ν有关,ν越小,t分布曲线越低平,尾部的面积较大;\nν∞不同自由度下t分布图\n注:所有的t分布的曲线均比正态曲线低。说明在同样的曲线下面积,t值>u值。例如,中间95%面积,在横轴上的区间:|u|=1.96;而|t|>1.96t值的表示方法:tα,να为界值以外的面积;ν自由度\n三、t界值表(附表2)对应每一自由度取值,就有一条t分布曲线,每条曲线都有自身曲线下t值的分布规律,因此,计算t值较为繁杂。为此,统计学家已制成t值表,通过查表即获得相应的t值。\n查表须注意:(1)t值有正负值,由于t分布是以0为中心的对称分布,故表中只列正值,查表时,不管t值正负只用绝对值;(2)t值表中插图阴影部分,表示tα,ν以外尾部面积占总面积的百分比,即概率P;\n(3)当ν一定时,P越小,t值越大;(4)当P一定时,ν越大,t值越小;ν=∞时,t=u;\n(5)当ν一定时,双侧P=2单侧P即双侧tα/2,ν=单侧tα,ν。单侧:t0.025,10=2.228双侧:t0.05/2,10=2.228二者相等\nα/2α/22(α/2)双侧单侧\n第三节总体均数估计一、可信区间的概念统计推断参数估计假设检验点估计区间估计用样本指标来估计总体指标\n参数估计的估计方法:1、点值估计:用样本均数来估计总体均数缺点:没有考虑抽样误差(可靠性)2、区间估计:按一定的概率α估计总体均数所在范围。1-α称可信度。习惯上,常取1-α=0.95,即95%可信区间或取1-α=0.99,即99%可信区间若无特别说明,一般取双侧95%可信区间\n总体均数的区间估计方法:(1)当σ未知,且n较小(n<30)时:(2)当σ已知,或σ未知但样本例数足够大(n>30)时,按正态分布原理处理:\n可信区间的两个要素:准确度:反映在可信度(1-α)的大小。1-α越接近1,就越准确。如可信度99%比95%准确。精确度:反映在区间的长度。长度越小越好。在例数n确定的情况下,二者呈反比关系:准确度↑,精确度↓(范围变宽)。要兼顾准确度和精确度,一般取95%可信区间。\n三、可信区间与参考值范围区别(1)意义不同:正常值范围是指绝大多数观察值在某个范围;可信区间是指按一定的可信度估计总体均数(参数)的所在范围;(2)计算公式不同可信区间正常值范围\n(3)应用不同可信区间:估计总体均数参考值范围:判断某项指标是否正常\n第四节假设检验的基本步骤一、假设检验原理例4.5μ0=72次/分已知总体μX=74.2S=6.0未知总体\n二、假设检验思想根据研究目的,对样本所属总体特征提出一个假设,然后用适当方法,根据样本提供的信息,推断此假设应当拒绝或不拒绝,以便研究者了解在假设条件下,差异由抽样误差引起的可能性大小。\n三、假设检验的一般步骤1、建立假设和确定检验水准2、选定检验方法和计算检验统计量3、确定P值和作出推断结论\n1、建立假设和确定检验水准基本步骤(1)两个假设无效假设:H0备择假设:H1(2)确定单侧或双侧检验根据专业知识和研究目的而定\n单侧检验:在比较两种药物的疗效时,根据专业知识可认为新药不会比旧药差,只关心新药是否比旧药好(至多相同,绝对排除出现相反的可能性),可用单侧检验。\n双侧检验:在比较两种药物的疗效时,事先不能确定哪种药的疗效较好,只关心两药的疗效有无差别,要用双侧检验。双侧检验若有差别,单侧检验肯定有差别;反之,单侧检验若有差别,双侧检验不一定有差别。\n(3)确定检验水准一般取α=0.05\n2、选定检验方法和计算检验统计量不同设计、不同的资料类型和不同的推断目的,选用不同的检验方法;\n3、确定P值P值是指由所规定的总体作随机抽样,获得等于及大于(或等于及小于)现有样本获得的检验统计量值的概率。手工计算:一般是通过查界值表获得。统计软件:直接给出精确的P值\n4、作出推断结论(含统计结论和专业结论)统计结论:拒绝H0,接受H1,差异有统计学意义)专业结论:可认为…不同或不等。当P≤α时,将获得的事后概率P与事先规定的概率α进行比较。\n当P>α时,统计结论:不拒绝H0,差异无统计学意义专业结论:还不能认为…不同或不等。\n假设检验的特点1、统计检验的假设是关于总体特征的假设;2、用于检验的方法是以检验统计量的抽样分布为理论根据的;3、作出的结论是概率性的,不是绝对的肯定或绝对的否定。\n假设检验中α值与P值的区别:1、假设检验中α值是检验水准,是拒绝或不拒绝H0的概率标准。α的大小是人为选定的,一般取0.05。2、P值是指有H0所规定的总体中作随机抽样,获得等于或大于(等于或小于)现有样本统计量的概率。通过P值与α值的比较来确定拒绝或不拒绝H0。\n第五节t检验和u检验t检验和u检验类型:1样本均数与总体均数的比较t检验2配对设计差值均数与总体均数0的比较t检验3两样本均数的比较t检验4两样本几何均数的比较t检验5两大样本均数比较u检验\n应用条件:1、t检验应用条件:(1)样本来自正态总体(2)两样本均数比较,还要求样本的总体方差相等2、u检验应用条件:样本例数n较大,或n虽小而总体标准差已知。\n一、单样本t检验样本均数代表的未知总体均数μ和已知总体均数μ0的比较μμ0=理论值、标准值、稳定值X\n公式:ν=n-1\n例4.6(对例4.5进行t检验)例4.5μ0=72次/分已知总体μX=74.2S=6.0未知总体\n检验步骤:例4.6①建立假设和确定检验水准H0:μ=72次/分H1:μ>72次/分单侧α=0.05今n=25,=74.2次/分,s=6.0次/分,μ0=72次/分\n例4.6②选定检验方法和计算检验统计量按式(4.10)v=n-1=25-1=24\n例4.6③确定P值以v=24查附表2,t界值表,得:t0.05,24=1.771,t0.025,24=2.064∵t0.05,24=1.771P>0.025(v一定时,t值越大,P值越小)\n查t值表时,先查P=0.05时的界值。当P<0.05时,需继续往P更小的一侧查,直到最小的P值为止。当P>0.05时,需继续往P更大的一侧查,直到最大的P值为止。如使用统计软件,会给出确切的概率值。注意\n例4.6④作出推断结论(两个结论:统计结论和专业结论)今0.05>P>0.025,按α=0.05水准,拒绝H0,接受H1(统计结论),可认为该山区健康成年男子脉搏均数高于一般健康成年男子脉搏均数(专业结论)。\n二、配对t检验(pairedt-test)(1)同对的两个受试对象分别给予两种处理(例4.7)(2)同一受试对象分别给予两种处理(同一标本用两种方法检测)(例4.8)(3)同一受试对象处理前后比较(例4.9)\n例随机选择9窝中年大鼠,每窝中取两只雌性大鼠随机地分入甲、乙两组,甲组大鼠不接受任何处理(即空白对照),乙组中的每只大鼠接受3mg/Kg的内毒素。分别测得两组大鼠的肌酐(mg/L)测定结果如下。窝别编号:123456789甲(对照)组:6.23.75.82.73.96.16.77.83.8乙(处理)组:7.53.86.34.35.37.35.67.97.2\n例检验血磷含量有甲、乙两种方法,其中,乙法具有快速、简便等优点。现用甲、乙两法检测相同的血液样品,所得结果如下表。问:检验甲乙两法检出血磷是否相同,用何统计方法?样本号1234567乙法2.740.541.205.003.851.826.51甲法4.491.212.137.525.813.359.61\n例某脑电图室观察家兔注射AT3前后脑电图波形的变化,观测结果如下。试分析注射AT3前后脑电图波形是否发生了显著性变化。注射AT3前后脑电图波形的变化率(%)家兔编号注射前注射后129372284433852429355344164143\n检验公式:\n例4.7配对号新药组安慰剂组差值(1)(2)(3)(4)=(2)-(3)14.46.2-1.825.05.2-0.235.85.50.344.65.0-0.454.94.40.564.85.4-0.676.05.01.085.96.4-0.594.35.8-1.5105.16.2-1.1-4.3新药组与安慰剂组血清总胆固醇含量(mol;/L)\n检验步骤:1、建立检验假设,确定检验水准H0:μ0=0H1:μ0≠0α=0.052、本例为配对计量资料,用配对t检验=-1.542ν=n-1=10-1=9\n3、确定P值以t=1.542,ν=9,查附表2,得0.1050)2、方法:样本均数与总体均数比较两样本均数比较\n第六节Ⅰ型错误与Ⅱ型错误Ⅰ型错误:拒绝实际上是成立的H0,这类“弃真”的错误称Ⅰ型错误或第一类错误。其概率大小用表示。Ⅱ型错误:不拒绝(接受)实际上是不成立的H0,这类“存伪”的错误称Ⅱ型错误或第二类错误。其概率大小用表示,但一般不知道.即拒绝H0,犯Ⅰ型错误;不拒绝H0,犯Ⅱ型错误。\n两类错误的关系:Ⅰ型错误的概率为α,Ⅱ型错误的概率为β,一般β的大小是不知道的。1-β:称为检验效能(又称把握度),即两总体确有差别,则按α水准能发现它们有差别的能力。α越大,β越小;α越小,β越大。呈反比关系\n如何确定α和β的取值?1、若重点减少α(例如,为避免把疗效与常规药本无差别的新药当做有差别,致使无故废弃常规药,即严格要求),则取α=0.01\n2、若重点减少β(例如,当欲用新方法取代旧方法时,为了慎重起见,宁可把无差别当成有差别),则取α=0.1或α=0.2。\n3、若需兼顾α和β,则取α=0.05较为恰当。4、若要同时减少α和β,只能增加样本的含量。\n第七节假设检验应注意的问题1、要有严密的抽样研究设计,应考虑到被比较的样本的可比性,这是假设检验的前提。2、选用的假设检验方法应符合其应用条件。\n3、正确理解差别有无显著性的统计意义。是否拒绝H0,取决于:1、被研究的事物有无本质的差异2、抽样误差大小:(1)个体差异大小(2)样本例数多少3、检验水准α的高低\n甲组(n=18)乙组(n=12)P值X±SX±S甲指标3.48±1.654.76±2.520.10乙指标5.23±1.126.38±1.210.01两均数相差1.28两均数相差1.15\n解释差值大小抽样误差大小变异度例数多少\n4、结论不能绝对化。即拒绝H0,犯Ⅰ型错误;不拒绝H0,犯Ⅱ型错误。无论是否拒绝H0,都可能犯错误!\n5、统计意义和实际意义有统计学意义,不一定有实际意义!\n第八节可信区间与假设检验的关系1、可信区间亦可用于回答假设检验问题2、可信区间比假设检验还可提供更多的信息。\n但这并不意味着可以完全用可信区间代替假设检验。假设检验得到的P值可以较精确地说明结论的概率保证,而可信区间只能告诉我们在α水准上有无统计意义,却不能象P值那样提供精确的概率。\n有实际意义有统计意义,可能有实际意义有统计意义,无实际意义无统计意义,样本例数太少确实无差别有实际意义值H0