

- 1.41 MB
- 2022-08-13 发布


- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
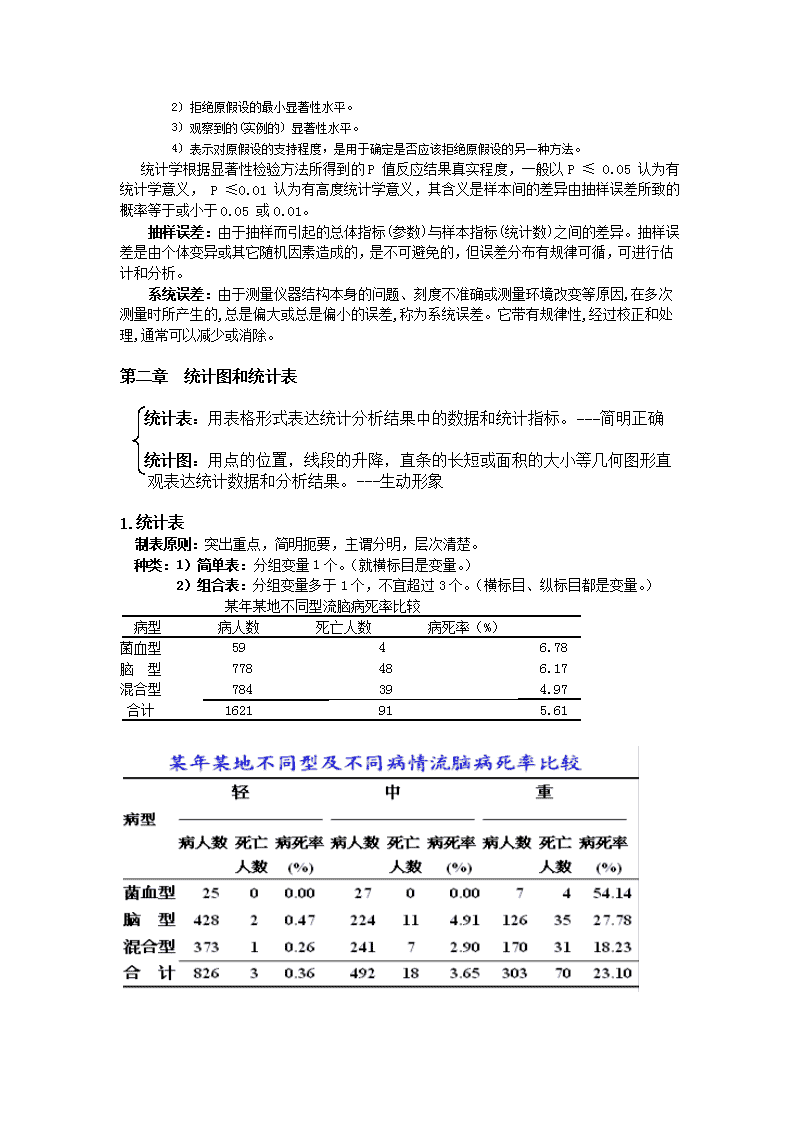
第一章绪论横断面研究1.统计学的基本内容和步骤:观察性研究病例对照研究队列研究①统计设计(关键):对研究对象的干预与否分为动物实验实验性研究临床研究试验社区干预试验②收集资料③整理资料统计描述:对特征客观描述,不从样本推总体,如均数,标准差④分析资料(基础)参数估计:样本统计量推断总体参数统计推断:根据样本推断总体假设检验:样本间差异推断总体是否差异实验设计的基本原则:1.随机化原则;2.对照的原则;3.重复的原则。2.总体和样本总体:是根据研究目的确定的同质观察单位(研究对象)的全体,实际上是某一变量值的集合。有限总体:时空限制根据有无时空限制分为无限总体:鱼塘里的鱼etc样本:从总体中随机抽取部分观察单位,其测量结果的集合。样本应具有代表性。所谓有代表性的样本,是指用随机抽样方法获得的样本。参数:反映总体指标统计量:反映样本得到的指标3.变量和概率离散资料定量资料:特征,数字大小,有单位计量资料变量连续资料有序:等级(学历)定性资料:文字,属性二项:性别无序计数资料多项:血型等级资料(有序变量):将观察单位按测量结果的某种属性的不同程度分组,所得各组的观察单位数。如患者的治疗结果可分为治愈、好转、有效、无效或死亡,各种结果既是分类结果,又有顺序和等级差别,但这种差别却不能准确测量;一批肾病患者尿蛋白含量的测定结果分为+、++、+++等。等级资料与计数资料不同:属性分组有程度差别,各组按大小顺序排列。等级资料与计量资料不同:每个观察单位未确切定量,故亦称为半计量资料。小概率事件:我们把概率小于0.05(即在大量重复试验中出现的频率非常低)的事件称为小概率事件。P值:P值即概率,反映某一事件发生的可能性大小。1)一种概率,一种在原假设为真的前提下出现观察样本以及更极端情况的概率。\n2)拒绝原假设的最小显著性水平。3)观察到的(实例的)显著性水平。4)表示对原假设的支持程度,是用于确定是否应该拒绝原假设的另一种方法。统计学根据显著性检验方法所得到的P值反应结果真实程度,一般以P≤0.05认为有统计学意义,P≤0.01认为有高度统计学意义,其含义是样本间的差异由抽样误差所致的概率等于或小于0.05或0.01。抽样误差:由于抽样而引起的总体指标(参数)与样本指标(统计数)之间的差异。抽样误差是由个体变异或其它随机因素造成的,是不可避免的,但误差分布有规律可循,可进行估计和分析。系统误差:由于测量仪器结构本身的问题、刻度不准确或测量环境改变等原因,在多次测量时所产生的,总是偏大或总是偏小的误差,称为系统误差。它带有规律性,经过校正和处理,通常可以减少或消除。第二章统计图和统计表统计表:用表格形式表达统计分析结果中的数据和统计指标。---简明正确统计图:用点的位置,线段的升降,直条的长短或面积的大小等几何图形直观表达统计数据和分析结果。---生动形象1.统计表制表原则:突出重点,简明扼要,主谓分明,层次清楚。种类:1)简单表:分组变量1个。(就横标目是变量。)2)组合表:分组变量多于1个,不宜超过3个。(横标目、纵标目都是变量。)某年某地不同型流脑病死率比较病型病人数死亡人数病死率(%)菌血型5946.78脑型778486.17混合型784394.97合计1621915.61\n统计表结构:1.标题:何时,何地,研究内容,左侧加表号,表上方。横标目:表头左侧,主语2.标目注明单位纵标目:表头右侧,谓语3.线条:三线(顶线,底线,纵标目下横线)4.数字:无数字:“---”;缺失:“…”;零:“0”5.备注:表格下方,*标示表麦芽根糖浆治疗161例急慢性肝炎疗效2.统计图:制作原则:1)正确使用适合的统计图2)长宽比例7:5或者5:7,圆图除外基本结构:1.标题:时,地,内容。2.标目:纵横标目代表纵横刻度意义,有度衡单位。3.刻度:纵横轴比例为7:5或者5:7。4.图例:右上角或者下方中间,表示图形所代表的事物。种类:1.圆图:表示事物各组成部分在总体中所占的比重。适用于描述定性分类变量的各类别所占的构成比。绘制:一般以圆的12点位置作为起点开始绘制,其它项放在最后。2.直条图:用等宽直条的长短表示某统计指标的数值大小和它们之间的对比关系适用于:比较、分析分类变量的多个组或类别的统计指标;两种:单式条图:1个指标,1个分组因素(人口,地区(1990))复式条图:1个指标,2个分组因素(人口,地区(1990,2000))绘制:通常横轴表示类别,纵轴表示比较的指标;起点为0的等宽直条\n;条间等距。3.直方图(频数分布图):是以直方面积描述各组频数的多少,面积的总和相当于各组频数之和。适用于:表示连续性定量变量的频数分布;绘制:纵轴刻度必须从0开始;各直条间不留空隙。如果各组组距不等,要折合成等距(即将频数除以组距得到单位组距的频数)后再绘图。4.箱式图:是用5个统计量反映原始数据的分布特征将数据的重要特征展示出来。箱子两端分别是上四分位数和下四分位数,中间横线是中位数,两端连线分别是除异常值外的最小值和最大值。另外,标记可能的异常值。箱子越长,表示数据变异程度越大。中间横线在箱子中间表示分布对称,否则不对称。特别适合于多组数据分布的比较。5.线图:是用线段的升降来表示数值的变化,适合于描述某统计量随另一连续性数值变量(如时间)变化而变化的情况。普通线图(横轴和纵轴都是算术尺度,描述绝对变化趋势)半对数线图(横轴是算术尺度,纵轴是对数尺度,描述相对变化趋势,特别适宜作不同指标变化速度的比较)----------可以不从0开始6.散点图:是以点的密集程度和趋势来表示两个变量间的数量关系通常横轴代表自变量,纵轴代表应变量;散点图与线图的不同点:对于横轴上的每个值,纵轴上可以有多个点与之相对应,且点与点之间不能用直线连接。7.统计地图:用不同的颜色和花纹表示统计量的值在地理分布上的变化适宜于:描述研究指标的地理分布;注意颜色或花纹的选择最好与统计量数值增减的趋势一致。第三章调查设计定义:分布状况和初步相关因素探讨适用:不大了解横断面研究现况调查目的:描述和分析特点:1.没有认为观察性研究(不干预)回顾性研究病例对照干预;2.不能将研1.医学研究究因素随机分配;实验性研究(干预)前瞻性研究队列研究3不提因果关系.\n2.主要内容和步骤明确研究目的(研究什么?为什么要研究?)根据研究目的作好调查研究的设计选择对象和样本含量估计(研究什么人?多少人合适?)确定调查的内容和方法(怎么去研究?)设计好调查表(使用什么工具来研究?)制订并完善项目实施规范制订并完善质量控制方案调查员(谁来调查?如何调查?)访问对象,填写调查表(实施调查)统计分析结果讨论写出报告3.调查设计题目----国家立题+个人立题原则:科学性原则;创新性原则;先进性原则;可行性原则;意义性原则4.调查方法:1)普查:1.是专门组织的全面调查(轻易不用);2.需要规定统一的调查时间(主要调查某一时点上的信息);3.获得的资料最全面、最系统,无抽样误差;*2)抽样调查:从总体中按照一定程序随机抽取一部分有代表性的单体作为样本进行调查,并以此来推断总体数量特征的一种数据收集方式。概率抽样方法:1.单纯随机抽样:最基本的抽样方法,是其它的基础,等概率,编号优点:均数和抽样误差计算简单缺点:编号比较麻烦,有时不可行2.系统抽样:固定间隔优点:简单、易行,可得到一个按比例分配的样本,抽样误差小于单纯随机抽样缺点:当总体的观察单位具有某种周期性或单调性增减趋势,容易产生明显的偏性,样本的代表性将大大下降。抽样误差的估计不精确。3.整群抽样:抽取若干个小的群体优点:简单易行、成本低、易于质控缺点:抽样误差最大(与其它三种抽样方法比较)4.分层抽样:优点:抽样误差最小(和其它三种抽样方法比较)不同层可用不同的抽样方法,可行性较好不同层可独立进行分析非概率抽样方法:1.偶遇;2.立意(判断);3.定额(配额);4.雪球5.搜集资料的方法:直接观察和访谈(面对面访谈、座谈会、信访)6.调查表:名称编号前言一般项目研究项目结尾分析项目(主体):主要用于体现研究目的,越详细越好研究项目备查项目:避免遗漏,主要用于核查分析项目的完整性和准确性,越简洁越好,可要可不要的坚决不要7.问题形式:\n封闭式问题:优点是答案标准化、易于回答、节约时间,一般拒答率低,记录汇总方便,可以进行定量分析;缺点是调查对象容易随便选答而丧失准确性,也难以得到答案以外的其它信息。开放式问题:优点是有利于调动调查对象的主观能动性,获得较丰富的信息;缺点是容易离题容易被拒绝,调查时间花费较多、不易整理与分析、难以互相比较等。设计问题一般原则:1、避免专业术语;2、避免语意模糊;3、避免双重问题;4、避免诱导性问题;5、问题的安排顺序符合逻辑8.资料整理分析计划9.样本含量估计:显著性水平(α水平,多为0.05):概率如小于该水平,即认为存在显著性差异把握度(1-β):能够发现某种确实存在的显著性差异的能力容许误差(最难确定):样本统计量与总体参数的最大差距应该控制在什么范围,即差距如果大于这个范围,即可认为存在显著性差异其它:率差、OR、RR。第四章计量资料的统计描述1.频数分布1)频数分布表2)频数分布图3)频数分布表和图的应用① 描述频数分布的类型(对称分布、偏态分布)(1)对称分布(2)偏态分布:1.右偏态分布(正偏态分布):右侧的组段数多于左侧的组段数,频数向右侧拖尾。比较高的在左边2.左偏态分布(负偏态分布):平均数小于中位数② 描述频数分布的特征:离散(变异)、集中(平均)③ 便于发现一些特大或特小的可疑值④ 便于进一步做统计分析和处理完备原则:第一组要求包含最小值,最后组包括最大值互斥原则:各变量不能一组出现2.集中趋势的描述1)算术均数(均数):直接法:加权法:适用于:1.正态或近似正态分布;2.均匀分布;3.对称分布特殊:离均差和为o,离均差平方和最小。2)几何均数:可用于反映一组经对数转换后呈对称分布或正态分布的变量值在数量上的平均水平。\n适用于:数值相差很大,成等比数列的资料,特别是服从对数正态分布资料。特殊:由于对数要正数,所以有o或者负数时,先加一个数使都大于0后得到的G减去这个数。3)中位数应用:1、各种分布类型的资料2、特别适合大样本偏态分布资料或者一端或两端无确切数值的资料。(分布未知或无端界,开口)4)百分位数1.直接法:100-x%2.频数表法:3.离散趋势的描述(极差、四分位数间距、方差、标准差和变异系数)1)极差(R):极差越大,变异越大应用:单峰对称,小样本,初步了解;相差大时,不宜用。2)四分位数间距四分位数间距,用Q表示:Q=应用:偏态,分布不明确,两端无确切值3)方差:均方差,反映一组数据平均离散水平总体:样本:4)标准差:频数表法:意义和用途:1.说明资料的离散趋势(或变异程度),标准差的值越大,说明变异程度越大,均数的代表性越差;...。标准差与原始数据的单位一致,在科技论文报告中,均数与标准差经常被同时用来描述资料的集中趋势与离散趋势。2.用于计算变异系数\n3.用于计算标准误(见第四章)4.结合均值与正态分布的规律,估计参考值的范围(见第五节)。5)变异系数:常用于比较度量单位不同或均数相差悬殊的两组(或多组)资料的变异程度。应用:单位不同,均数相差悬殊4.正态分布(高斯分布)特征:1.在直角坐标上方呈钟型曲线,两端与X轴永不相交,且以为对称轴,左右完全对称。2.在处,取最大值,其值为;X越远离,值越小。3.正态分布有两个参数,即位置参数和形态参数。若固定,改变值,曲线沿着X轴平行移动,其形状不变。若固定,越小,曲线越陡峭;反之,越大,曲线越平坦。4.正态曲线下面积分布有一定的规律,总面积=1。1)X轴与正态曲线所夹面积恒等于1或100%;2)区间的面积为68.27%;3)区间的面积为95.00%;4)区间的面积为99.00%。应用:1.估计总体频率分布;2.制定参考值范围里;3.质量控制(警戒线2s和控制线3s)面积标准正态分布正态分布68.27%-1----+195.00%-1.96------+1.9699.00%-2.58----+2.58-1、正态分布的判断和检验:a.根据正态分布的特点判断首先看频数分布是否对称,其次计算±1.96S,看其是否包括约95%的观察值,如果是可初步判断为正态分布,否则判为非正态。b..用正态概率纸法进行检验\n正态概率纸的横轴为算术尺度,纵轴为概率单位尺度。2.估计数频分布5.参考值范围:正常值指正常人(或动物)的各种生理常数,包括人体的形态,机能及代谢产物,生理生化指标,由于个体差异,这些生理常数有一定的波动范围,因此,一般采用正常值范围。制定参考值原则与基本内容(基本步骤)1)明确参考值的适应范围条件:2)根据研究的指标,选择“正常人”作为观察对象3)选择一批病人作为参照人群4)统一测量方法与条件,控制测量误差5)确定观察例数(样本含量)6)按年龄,性别分别制定正常值范围。7)决定单侧或双侧的正常值范围8)选定合适的百分界限,正态分布法百分位数法,9)对资料的分布进行正态正态性检验。10)根据资料的分布类型制定适当的方法参考值范围的估计方法双侧单侧双侧双侧单侧正态分布法百分位数法单侧下界单侧上界单侧上界单侧下界90%
95
99P90P95P99第四章定性资料的统计描述1.常用想对数及应用1)率:频率和速率2)构成比3)相对比关系指标:非同类,有关系对比指标:同类,2个指标相对危险度(RR)=暴露组累积发病率(或死亡率)/对照组累积发病率(或死亡率)说明暴露组发病或者死亡的危险性是非暴露组的倍数,RR值越大,表明暴露的效应越大,暴露与结局的关联的强度越大。比值比(优势比)=病例组暴露比值/对照组暴露比值=(a/c)/(b/d)=ad/bc度量暴露危险度应用:1.计算相对数有足够的观察数;2.分析不可用构成比代替率;3.应将分子分母合计求率;\n4.注意相对数可比性;5.样本率或构成比做假设检验2.率的标准化1.直接法:Ni:标准年龄别人口数Pi:实际年龄别××率N:标准人口总数2.间接法:P:标准总死亡率ΣniPi:预期总死亡数r:实际总死亡数r/ΣniPi(SMR):标准化死亡比ni:实际组别人口数Pi:标准年龄别死亡率SMR:标准化死亡比,>1,被标化组死亡数高于标准组第五章总体均数的估计一.抽样误差及标准误中心极限定律:1)在正态的总体中抽样,个体更多倾向于总体2)从偏态中抽样,随样本量增大,分布趋向正态样本抽样分布的特点:1.各样本均数未必等于总体均数;2.均数样本存在差异;3.分布规律:总体均数周围围绕,中间多,2边烧对称;4.变异范围较原变量范围少;5.样本增多,变异范围逐渐减小。标准差描述个体值的变异程度(用途书)意义:标准差越小,个体值越集中,均数对数据的代表性越好应用:1.表示观测值的变异程度;2.计算变异系数;3.确定参考值范围;4.计算标准误标准误(SEM):样本均数的标准差,可用于衡量抽样误差的大小(用途书)。因为σ不知道,意义:标准误越大,均数分布越分散,样本均数和总体均数的差别越大,抽样误差越大,资料可靠性越小。应用:1.用于衡量样本可靠性;2.用于总体均数区间估计;3.均数的假设检验标准差和标准误的区别:1.符号不同;2.计算公式不同;3.统计学意义不同\n4.用途不同二.t分布正态分布中抽取样本n个均服从正态分布,得,我们称为u分布。但是实际中标准误不知道,多用Sx拔估计,这时就是t分布。特征:①以0为中心,左右对称的单峰分布;②t分布曲线是一簇曲线,其形态变化与自由度的大小有关。自由度越小,则t值越分散,曲线越低平;自由度逐渐增大时,t分布逐渐逼近U分布(标准正态分布);当趋于∞时,t分布即为U分布。面积规律:1.t分布曲线下的整个面积为1(100%)2.当n=∝时,t分布趋向于标准正态分布,即均数为0,S为1的正态分布;3.t值在±1.96范围内的面积占95%,4.在±2.58的范围内占99%,3.总体均数的可信区间估计点估计:由样本统计量直接估计总体参数参数估计(量)总体均数估计区间估计:在一定可信度下,同时考虑抽样误差显著性检验(质)按预先给定的概率(1-ɑ),确定一个包含未知总体参数的范围。这一范围称为参数的可信区间或置信区间。(1-ɑ)称为可信度或置信度(confidencelevel),常取95%。总体均数置信区间的计算:1.s未知,且n较小,按t分布2.s已知,或s未知但n足够大,按U/Z分布\nZ0.05/2=1.96Z0.05=1.645三.总体均数可信区间与参考值范围的区别准确度(1-α),99%比95%好总体均数的置信区间精密度Cl~Cu衡量,95%比99%好第六章假设检验1.基本思想:总体均数的假设检验有二个目的的。a)推断单个总体均数μ是否等于已知总体均数.b)推断两个总体均数μ1和μ2是否相等.造成平均数x拔和μ0或x1拔与x2拔的差别有二种情况。a)完全由抽样误差造成,即μ=μ0,或μ1=μ2这种情况差别相对小,称为无显著性。b)除了由抽样误差造成外,造成总体均数差别.即μ≠μ0或,μ1=μ2这种情况差别相对大,称为差别有显著性。2.步骤1)建立检验假设:a)μ=μ0称无效假设,用Ho表示;b)μ≠μ0称备择假设,用H1或HA表示,2)确定检验水准:称为显著性水准,用α表示一般取α=0.05。3)选定方法,计算统计量:根据变量或资料类型,设计方案.检验方法的适用条件等选择检验方法。4)确定P值作出推断结论:\n根据计算出的检验统计量,查相应的界值表即可得概率P。若P≤α则结论为按所取的α检验水准,拒绝Ho,接受H1有统计学意义(统计结论)可以认为不同或不等。注意:1)检验假设是针对总体而言,而不是针对样本;2)Ho和H1是相互联系,对立的假设.结论是根据Ho和H1作出的;3)Ho为无效假设,其假定是某两个(或多个)总体参数相等,或某两个总体参数之差等于另或;4)H1的内容反映出检验单双侧,若H1假设为μ>μ0,则检验为单侧检验.两型错误真实情况拒绝Ho不拒绝HoHo正确I型错误(弃真,误诊)推断正确(1-α)Ho不正确推断正确(1-β)II型错误(存伪,漏诊)注意:在样本量一定时,α和β同大同小;样本量增大时,都减小。检验效能(1-β)一般在0.8以上,如果重点减少犯I型错误,α=0.01;如果减少II型错误,α=0.05或者α=0.10单侧和双侧检验的选择(分析目的与专业知识选择)双侧:无差异,不比优势单侧:比优劣,比双侧更易获有统计学意义本来应该用双侧用单侧,是I型错误假阳性。注意问题:1.数据来自设计科学严密的实验或调查;2.数据应该满足检验方法的前提条件(独立,正态,方差齐);3.不能认为p值减小,总体参数差别越大;4.结论不能绝对化(因为有I型II型错误在);5.统计学意义与实际意义。假设检验用以推断两总体均数是否相同,而可信区间则用于推断总体均数在哪个范围。第七章t检验应用条件:1.单样本t检验,总体标准差σ不知且样本含量(n<50)时,要求样本来自正态分布总体;2.两小样本均数比较时,要求两样本均来自正态分布总体,且两样本总体方差相等,如果不等,用t’检验;3.对两个样本均大于50的均数比较,用z检验。1)样本均数与总体均数的比较已知健康成年男子脉搏均数为72次/分,现某医生在一山区随机抽查了25名健康成年男子,求得脉搏均数为74.2次/分,标准差为6.0次/分,问山区成年男子的脉搏均数高于一般成年男子脉搏均数?a)建立检验假设,确定检验水准Ho:μ=μo=72次/分H1:μ>μoα=0.05b)选定检验方法,计算检验统计量t值。=74.2次/分S=60次/分μ=70次/分代入公式\nυ=n-1=25-1=24c)确定P值,作出推断结论υ=24,查t值表,因t0.0524=1.711<1.833故单尾概率P<0.05按α=0.05拒绝Ho接受H1有统计意义,可认为该山区健康成年男子脉搏数高于一般成年男子脉搏数。2)配对t检验配对设计主要有以下情形(有三种情况)a)自身比较是指同一受试对象处理前后的比,目的是推断这种处理有无作用。b)同一样品用两种方法检验的结果。c)成对设计的两个受试对象分别给予两种处理,目的都是推断两种处理的效果有无差别.1.应用某药治疗8例高血压患者,观察患者治疗前后舒张压变化情况,如表9-10,问该药是否对高血压患者治疗前后舒张压变化有影响表9-10某药治疗高血压患者前后舒张压变化情况病人舒张压(mmhg)差值编号治疗前治疗后d19688821121084310810264102984598100-26100964710610241)建立假设,确定检验水准2)选择检验方法,按公式9-24计算检验统计量t值3)确定P值,判断结果\n自由度υ=n-1=8-1=7,查表9-9t界值表今4.02>2.365,故P<0.05故按a=0.05水准,拒绝H0,接受H1,可认为该药有降低舒张压的作用。3)两个样本均数的比较:a)两个大样本均数的比较,当两个样本含量较大(均>50)可用μ检验,目的是推断它们各自代表的总体均数有无差别,按公式(9-25)计算检验统计量u值为两样本均数差值标准误,或叫合并标准误某地随机抽取正常男性新生儿175名,测得血中甘油三酯浓度的均数为0.425mmol/L,标准差为0.245mmol/L;随机抽取正常女性新生儿167名,测得血中甘油三酯浓度的均数为0.438mmol/L,标准差为0.292mmol/L,问男、女新生儿甘油三酯浓度有无差别?(1)建立检验假设,确定检验水准b)两个小样本均数的比较可用于样本含量较小时,且要求两正态总体方差相等,公式: (2)选择检验方法,按公式9-25计算检验统计量u值2)选择检验方法计算检验统计量u值为两样本均数差值的标准误为合并方差\n两组雄性大鼠分别饲以高蛋白和低蛋白饲料,观察每只大鼠在实验第28天到84天之间所增加的体重,见表9-11。问用两种不同饲料喂养大鼠后,体重增加有无差别表9-11用两种不同蛋白质含量饲料喂养大鼠后体重增加的克数高蛋白组低蛋白组X1X2(平方)X2(右下角的)X21341795670490014621316118139241041081610110201119141618572251241537610711449161259211321742410711449948836836889113127691291664197940912315129144017783270773959(3)确定P值,判断结果表2t界值表今1.891<2.110,故p>0.05,按α=0.05水准,不拒绝Ho,尚不能认为两种不同蛋白质含量饲料喂养大鼠后体重增加是不同的。C)方差不齐时两小样本均数比较1.)两样本方差的齐性检验\n用t检验进行完全随机设计两总体均数比较时,要求两总体的方差相等。因此在做两总体样本均数比较的t检验前,首先应对两总体的方差是否相等进行检验。方差相等称为方差齐性,方差检验的适用条件是两样本均来自正态分布的总体为了方便,通常是用较大方差比较较小方差,因此构造了统计量F, t’检验(t’检验—近似t检验)近似t检验有3种方法可供选择,包括Cochran&Cox法、Satterthwaite法和Welch法。其中第1,2种方法较为常用。现选择Cochran&Cox法(1950)该法是对临界值校正,其检验统计量t’为D)成组设计的两样本几何均数的比较为比较两种狂犬病疫苗的效果,将120名患者随机分为两组,分别注册精制苗和PVRV,测定45天两组的狂犬病毒抗体滴度,结果见表3.4,问两种狂犬病疫苗的效果有无差别?表3.42种疫苗狂犬病毒抗体滴度的比较疫苗血清滴度人数类型5010020040080016003200640012800精制苗601337462673PVRV60131410531590(1) 建立检验假设,确定检验水准Ho:两种疫苗的总体几何均数对数值相等H1:两种疫苗的总体几何均数对数值不等α=0.05(2)计算统计量将两组数据分别取对数,记做X1,X2。\n用变换后的数据计算,S1,。S2。X1=3.2292,S1=0.5714,X2=2.9482。S2=0.6217代入式(3.8)V=60+60-2=118(3) 确定P值,作出统计推断查附表2,t界值表,得0.010.05不拒绝H0,差异无统计学意义≥χ20.05(v)0.05拒绝H0,接受H1差异有统计学意义≥χ20.01(v)0.01拒绝H0,接受H1,差异有统计学意义四.四格表资料的χ2检验(一)四格表资料的χ2检验的基本步骤以例10-8.某医生用A,B两种药物治疗急性下呼吸道感染,A药治疗74例,有效68例,B药治疗63例,有效52例,结果见表10-7。问两种药的效率是否有差别表10-7两种药治疗急性下呼吸道感染有效率比较处理有效无效合计有效率(%)A68(64.82)6(9.81)7491.89B52(55.18)11(7.82)6382.54合计1201713787.591建立检验假设:Ho:π1=π2,H1:π1≠π2,;α=0.05。2.计算理论数和χ2统计量(理论数已计算)3.确定P值和判断结果:v=(行数-1)(列数-1)=(2-1)(2-1)=1,根据自由度查χ2界值表,χ20.05(v)=3.84,本例χ2=2.734<3.84,P值>0.05,按α=0.05水准不能拒绝无效假设H0,(二)四格表资料专用公式四表格资料进行χ2检验还可以选用专用公式(由公式推导而来)省去计算理论数的过程,使计算简化式中a,b,c,d分别为四格表中的四个实际频数,n为总例数.计算结果同前\n(三)四格表资料的χ2检验的校正公式一般情况下是否进行连续性校正遵循以下条件:(1)T≥5,且N≥40时,用不校正公式计算χ2值(2)1≤T<5,且N≥40时,用连续性校正χ2检验(3)T<1或N<40,用Fisher精确概率法例题:某医生收集到两种药物治疗白色葡萄球菌败血症疗效的资料,结果见表10-8,问两种药物疗效之间的差别有无统计学意义?表10-8两种药物治疗白色葡萄球菌败血症结果处理有效无效合计有效率%甲药28(26.09)2(3.91)3093.33乙药12(13.91)4(2.09)1675.00合计4064686.961.建立假设H0:两疗法有效率相等即π1=π2,H1:π1≠π2,,а=0.052.计算χ2值本例先按式10-15进行计算行合计与列合计的乘积最小值所对应的格子的理论数,得T22=16×6/46=2.09本例至少有一个格子的理论数小于5总例数n=46>40,故用连续性公式计算χ2值3确定P值和判断结果v=(2-1)(2-1)=1,查χ2表,P>0.05,故还不能认为两种药物治疗白色葡萄球菌败血症的效率有差别五.四格表配对资料的x2检验是配对对设计研究所获得的计数资料进行比较。配对设计包括:①同一批样品用两种不同的处理方法;②观察对象根据配对条件配成对子,同一对子内不同的个体分别接受不同的处理;病因或危险因素。若观察的结果只有阴性、阳性两种可能,清点成对资料时发现只有四种情况:(a)甲+乙+(b)甲+乙-(c)甲-乙+(d)甲-乙-。\n例题:有65个可疑糖尿病人的空腹静脉血标本和晨小便标本,分别用生化测定方法和尿糖试纸测定血糖,观察空腹静脉血标本和小便检查糖尿病的差别情况,结果如下表,试比较两种方法的效果。(注:空腹静脉血血糖)7.78mmol/L为阳性,用“+”表示,小便糖尿呈显+,++及以上均记为阳性,也用“+”表示)两种方法检查糖尿病的效果比较空腹静脉血尿糖+—合计+37(a)5(b)42—10(c)13(d)23合计471865空腹静脉血糖的阳性率为47/65=72.31%,糖尿的阳性率为42/65=64.62%,若检验两种培养基的培养效果有无差异,(a)和(d)是两种方法的检验结果一致数,对比较差异的显著性无作用,仅考虑检验结果不一致的(b)和(c)。采用下列公式若b+c>40可用公式:1.检验假设Ho:B=C,H1:B≠C,α=0.052.计算χ2值 3.确定概率P值和判断结果配对四格表资料的自由度v=1,查χ2值表,χ20.05(1)=3.84,χ2 <χ20.05(1),P>0.05,不能拒绝Ho,根据本资料尚不能认为两种方法检查糖尿病效果有何不同。六.行x列表资料的χ2检验有两个或两个以上比较的组,记录的观察结果也有两个或两个以上,如比较两格治疗组的疗效,观察结果为有效、无效和死亡。行x列表资料的χ2检验解决两个以上的率(或构成比)差异的比较N为总例数,A为每格例的实际频数,nR和nc分别为与A值相应的行和列合计的例数。例子:某研究组欲研究父母感情好坏与女儿吸毒的关系.调查了吸毒组和对照组的父母的感情,结果如表.试分析父母感情与女儿吸毒的关系。吸毒组和对照组的父母的感情父母感情组别恩爱%一般%紧张或离异%合计病例组10533.8712841.297724.84310对照组27276.197922.1361.68357合计37720783667\n1.检验假设Ho:吸毒和对照组父母各种不同感情状况的构成比相同;H1:吸毒和对照组各种不同感情状况的构成比不同;α=0.052.计算χ2值3.确定概率P值和判断结果v=(3-1)(2-1)=2,查χ2值表,χ20.05(2)=5.99,χ20.01(2)=9.21,χ2<χ20.01(2),P<0.01,按α=0.05水准,拒绝无效假设Ho,接受备选假设H1,认为父母感情好坏与女儿吸毒有关系,吸毒组父母感情一般、紧张或离异所占的比例高于对照。行x列表资料的χ2检验的注意事项.1.如假设检验的结果是拒绝无效假设,只能认为各总体率或构成比之间总的来说有差别,但并不是说它们彼此之间都有差别。如果想进一步了解彼此之间的差别,需将行x列表分割,再进行χ2检验(详见统计学专著)2. 对行x列表资料的χ2检验,要求不能有1/5以上的格子理论数小于5,或者不能有一个格子的理论数小于1,否则易导致分析偏性。出现这些情况时可采取以下措施:①再可能的情况下再增加样本含量;②从专业上如果允许,可将太小的理论数所在的行或列的实际数与性质相近的邻行中的实际数合并;③删去理论数太小的行和列。第十章秩和检验一.概念1参数检验:总体分布类型已知的条件下,对其参数进行估计或检验.2非参数检验:一种不依赖总体分布的具体形式,也不对参数进行估计或检验的统计方法来分析此类资料。这种方法不受总体参数的影响,他检验的是分布或分布的位置,而不是参数。这样的检验方法称之为非参数检验。3.优点:无严格的条件限制,且多数非参数统计方法较为简便,易于理解和掌握,故而应用范围广。4.缺点:但对适宜参数统计的资料,若用非参数统计处理,常损失部分信息,降低检验效能.二.配对设计差值的符号秩和检验---配对法例子:对10名健康人分别用离子交换法与蒸馏法,测得尿汞值,如表11-.1中的(2)、(3)栏,问两法所得结果有无差别?\n表11-110名健康人用离子交换法与蒸馏法测定尿汞值(μg/l)编号离子交换法蒸馏法差数秩次(1)(2)(3)(4)=(2)-(3)(5)10.50.00.5222.21.11.1730.00.00.0—42.31.31.0656.23.42.8861.04.6-3.6-971.81.10.73.584.44.6-0.2-192.73.4-0.7-3.5101.32.1-0.8-5T+=26.5T-=18.5检验步骤:(1) 检验假设:Ho:差值总体中位数Md=0H1:Md≠0α=0.05(2)求差值:(3)编秩:差值的绝对值从小到大编秩遇差数等于零,舍去不计,同时样本例数减1;遇绝对值相等差数,符号相顺次编秩,符号相反取平均秩次。(4)求秩和并确定检验统计量T(5)确定P值和作出推断结论当n≤25(n≤50)时,查附表T界值表。统计量值大于表中相应的界值时,则P<0.05;否则P>0.05正态近似法:若n≥25(n>50)超出附表11-2的范围,可用u检验,按公式(11-1)计算u值,式中,分子0.5;连续性校正数,因为T值是不连续的,而u分布是连续的,这种校正,一般影响甚微,常可略去.当相同“差值”(计绝对值)数多时(不包括差值为0值),用式(11-.1)求得的u值偏小,应改用校正式。三.两样本比较的秩和检验------两样本比较法\n本法是通过两个样本的观察值来推断两个总体的分布位置是否相同,其检验假设是两个总体的分布位置相同,备择假设是两个总体的分布位置不同。其基本步骤如下:1建立假设2编秩3求含量较小的样本秩和T4.确定P值判断结果1).查表法:查表时,统计量T值在上、下界值范围内其P值大;若T值在上、下界值范围外,其P值小,若T值等于上、下界值范围,其P值小于表中相应得概率。2)正态近似法:如果样本含量较大,表中查不到时,可用正态近似法作检验,公式为:当相同秩次较多时,按式11-3计算得u偏小,应采用矫正公式:例1:直接法为了比较甲乙两种香烟得尼古丁含量(mg),对甲种香烟做了6次测定,对乙种香烟做了8次测定,数据见表11-3第(1)、(3)列,问这两种香烟得尼古丁含量有无差别?表11-3两种香烟尼古丁含量得秩和检甲种香烟秩次乙种香烟秩次256289.5289.5311323430122673214291121222327825201N1=6T1=40.5N2=8N3=64.51. 建立假设:H0:两总体分布相同,或两总体位置分布相同H1:两总体位置分布不同α=0.052.编秩:将全部14个观察值从小到大标出其秩次,见表11-3第(2)、(4)栏。中甲乙两种香烟测定值均有28,则应取其平均秩次是. 3计算:以样本含量较少得组得秩和为T,本例n1=6,n2=8,T=40.5\n4确定P值:判断结果查表11-4两样本比较秩和检验用T界值表,双侧检验,当n1=6,n2-n1=8-6=2时,40.5在29~61之间,P>0.05按α=0.05水准不拒绝H0尚不能认为良种香烟得尼古丁含量有差别。基本思想:假定含量分别为n1和n2得两个样本来自同一总体(或分布相同得两个总体),则样本含量为n1的样本的T与平均秩和一般应相差不大.如相差悬殊,超出了表11-4,按α水准的界值范围,表示随机抽得现有样本统计量T值得概率很小,因而在α水准上拒绝无效假设H0;相反,若P大于α则不能拒绝无效假设H0。例2---频数表法例11-3:用某药治疗不同病情的老年慢性支气管炎患者,疗效见表11-5第(1)、(2)两栏,此药对两种病情的老年慢性支气管炎患者的疗效有无差别.。表11-5某药对两种病情的老年慢性支气管炎患者的疗效疗效单纯性单纯性合计秩次范围平均秩次秩和合并肺气肿单纯性合并肺气肿控制65421071----1075435102268显效18624108—131119.52151717有效302353132---18415847403634无效131124185----208242554.52161.5合计12682208R12955.58780.51、建立假设Ho:两个总体的疗效分布位置相同H1:两个总体的疗效分布位置不全相同α=0.052.编秩3求秩和对于单纯慢性支气管炎组:R=(65x54)+(18x119.5)+(30x158)+(13x196.5)=3510+2451+4740+2554.5=12955.5对于单纯性合并肺气肿的慢性支气管炎组:R=(42x54)+(6x119.5)+(23x158)+(11x196.5)=2268+3634+2161.5+8780.5=8780.5此例n1=82n2=126n1-n2=44,代入公式:4、确定P值,判断结果本例uc=0.541,0.541<1.96,故P>0.05,按α=0.05水准,不拒绝Ho,可认为该疗法对以上两种病情的老年慢性支气管炎患者的疗效尚看不出差别。当经过多个样本比较的秩和检验拒绝无效假设,认为各总体分布位置不同或不全相同时,常需进一步两两比较\n四.多个样本比较得秩和检验-------H检验本法利用多个样本的秩和推断各样本分别代表的总体的位置有无差别(即个总体的变量值有无倾向性的不同)。它相当于单因素方差分析的非参数方法,此法适用于有序分类资料及不宜用参数检验(F检验)的数值变量资料,该法亦称为H检验。包括直接法和频数表法步骤:1.建立假设;2.编秩;3.求秩和(分组计算秩和);4.计算检验h,公式;5.p值,得结果例1-------直接法某医院外科用三种手术方法资料肝癌患者15例,每组5例,进入各组得患者系用随机方法分配,每例术后生存月数如表11-5得第(1)、(3)、(5)栏。试问三种不同手术方法治疗肝癌的效果有无差别?表11-5三种手术方法治疗肝癌患者的术后生存月数甲术后秩次乙术后秩次丙术后秩次生存月数生存月数生存月数3491311710121522.5710111467.567.58124522.556710Ri346026Ni5551.建立假设H0:三个总体分布位置相同H1:三个总体分布位置不同或不全相α=0.052.编秩见表11-5第(2)(4)(6)栏。3. 求秩和见表11-5下部。4.计算检验统计量H值本例先按式11-5计算5.确定P值,判断结果:求得H值后,查表11-7(326页)三组比较秩和检验H界值表.当样本数或ni超出表中范围时,H得分布近似于自由度为样本减1得X2分布,可查X2界值表,得P值,最后按所取检验水准做出推断结论如在编秩时未遇到相同得数值需计算平均秩次,就可以此H值与相应得临界值比较做出判断.否则要按下公式计算Hc值后再做判断。Hc=H/C式(11-6)\n本例有两个2(平均秩次2.5),两个6(平均秩次均为7.5)和三个7(平均秩次均为10),故t1=2,,t2=2,t3=3代入按式11-6计算较H值增大,但相差甚微。查表11-7H界值表,本例N=15,n1,n2,n3,均等于5,H0.05=5.78,Hc=6.39,6.39>5.78则P<0.05按α=0.05水准拒绝Ho,接受H1,三种手术方法后生存月数不同。例2----频数表法若样本含量较多,尤其是等级资料,各样本可制成统一组段的频数表进行秩和检验。属于同一组段或等级的观察值,一律取平均秩次,再以各组段的频数加权;由于此时重复的秩次较多,更需要计算矫正的Hi值某研究者调查了分娩时孕周与乳量的关系,数据见表11-7的表(1)-(4)栏,比较分娩时孕周与乳量的关系表11-7分娩时孕周与乳量的关系 乳量早产足月产过期产合计秩次范围平均秩次秩和早产足月产过期产无30132101721----17286.5259511418865少3629214342173-514343.5123661003024809多3141434479515—9937542337432115625636合计97838589933833542387631310 1.建立假设H0:三个总体分布位置相同H1:三个总体分布位置不同或不全相同α=0.052.编秩求各级别合计数及平均秩次3.求秩和4.计算h值5.确定p值判断结果X2界值表,,今14.3>5.99,故P<0.05,按α=0.05水准,拒绝Ho,接受H1可认为分娩时孕周对乳量是有影响的。\n由于每个级别的频数(即相同秩次的个数)较多,本例应按式11-6计算校正的Hc值,即:查X2值表,得P<0.05,显然与前面所做出得结论一致,可认为分娩时孕周对乳量是有影响.五.多个样本间两两比较的秩和检验当多个样本比较的秩和检验其结论认为各个总体的分布位置不同时,常需进一步作两两比较的秩和检验,以推断哪两个总体的分布位置不同,哪两个总体间没有这种差别。有很多种两两比较的方法,本节介绍的是扩展了的t检验。υ=N--K例题:某医院外科用三种手术方法治疗肝癌患者15例,每组5例,每例术后生存月数见表11-6(325页)第(1)(3)(5)列。经多个样本比较得秩和检验,各组间有差别,试再进一步作两两比较。1. 建立假设H0:任何两个总体分布位置均相同H1:任何两个总体分布位置不同或不全相同α=0.052. 计算各样本得平均秩次。3列出两两比较得秩和检验计算表见表11-9,表中第(5)栏t值按式11-7计算。本例N=15,K=3,前面例11-3中已求得Hc=6.39,故1组和2组比较时其余计算结果见表11-8表11-811-5资料两两比较得秩和检验样本含量两平均秩次之差TpA与BnAnB\n1与2555.22.31<0.051与3551.60.71>0.052与3556.83.02<0.054.确定P值,判断结果根据各对比组得t值及自由度v=N-K=15-3=12,查表9-9t界值表得出P值,见表11-6第(6)栏。按α=0.05水准,除了1组与3组比较,不拒绝H0,即甲法与丙法两者无差别,其余每二者间均有差别,可认为乙法优于甲、丙法.小结:1、参数统计方法:参数统计方法是一类依赖与总体分布的具体形式的统计方法。2、非参数统计方法:非参数统计方法是一类不依赖与总体分布的具体形式的统计方法。3.秩和检验操作步骤1)、建立检验假设计算差值编秩次计算秩和确定p值和作出推断结论2)、秩和检验统计量判断:①样本含量不多其结果查有关附表②样本含量超过附表判断其分布趋向正态,按正态公式去求统计量其结果按1.96和2.58去判断3)、秩和检验计算分直接法与频数法,注意直接法和频数法编秩次方法不一样。4)、频数法检验因相同秩次较多,一般其结果多必须用校正公式计算为好5)、多组资料的H检验注意,若只有三组,每组例.数≤5查H界值表确定P值,若组数K>3,样本例数军≥5H近似服从v=k-1的x2分布,应查卡方界值表确定P值6)、多个样本秩和检验如有意义,必须做多个样本两两比较。第十一章直线相关与回归一.概念回归与相关:变量间关系问题:年龄~身高、肺活量~体重、药物剂量与动物死亡率等。两个关系:依存关系:应变量(dependentvariable)Y随自变量(independentvariable)X变化而变化。——回归分析互依关系:应变量Y与自变量X间的彼此关系——相关分析X:自变量,解释变量。只有一个叫简单回归,多个叫多元回归。Y:因变量,反应变量。二.直线回归回归关系:例如血压和年龄的关系,称为直线回归。\n目的:建立直线回归方程直线回归方程一般表达式:a:截距,直线与Y轴交点的纵坐标。b:斜率,回归系数。意义:X每改变一个单位,Y平均改变b个单位。b>0,Y随X的增大而增大(减少而减少)——斜上;b<0,Y随X的增大而减小(减少而增加)——斜下;b=0,Y与X无直线关系——水平。|b|越大,表示Y随X变化越快,直线越陡峭。最小二乘法原则:使各散点到直线的纵向距离的平方和最小,即使最小。参数计算实例:编号母X脐YX2Y2XY11.213.901.464115.21004.719021.304.501.690020.25005.850031.394.201.932117.64005.838041.424.832.016423.32896.858651.474.162.160917.30566.115261.564.932.433624.30497.690871.684.322.822418.66247.257681.724.992.958424.90018.582891.984.703.920422.09009.3060102.105.204.410027.040010.9200合计15.8345.7325.8083210.731973.1380SXSYSX2SY2SXY三.回归系数的假设检验b≠0原因:①由于抽样误差引起,总体回归系数β=0②存在回归关系,总体回归系数β≠0(一)t检验;\n公式,υ=n-2Sb为回归系数的标准误SY.X为Y的剩余标准差——扣除X的影响后Y的变异程度。(二)方差分析SS总=SS回归+SS残差SS残差越小,SS回归越大,表明回归模型的预测效果越好。MS回归=SS回归/1=SS回归,MS残差=SS残差/(n-2)F=MS回归/MS残差三.直线回归方程的区间估计四.回归方程的应用1.预测(给定X值,估计Y)2.控制(给定Y值范围,求X值范围)五.直线相关回归----变量间的依存关系相关----变量间的互依关系直线相关:简单相关,用于双变量正态分布资料。散点呈椭圆形分布,X、Y同时增减---正相关;X、Y此增彼减---负相关散点在一条直线上,X、Y变化趋势相同----完全正相关;反向变化----完全负相关。X、Y变化互不影响----零相关六.相关系数概念相关系数又称积差相关系数或相关系数,说明相关的密切程度和方向的指标。r——样本相关系数\nr无单位,-1≤r≤1。r值为正——正相关,为负——负相关;(与回归系数b的符号相同)|r|=1---完全相关,|r|=0---零相关。七.相关系数的假设计算八.相关系数的假设检验r≠0原因:①由于抽样误差引起Sr-相关系数的标准误②存在相关关系v=n-2对于同一资料,tb=tr,检验完全等价九.直线回归与相关的区别与联系区别:1.资料,Y正态随机变量,X为选定变量X、Y服从双变量正态分布2.应用:回归——由一个变量值推算另一个变量值相关——只反映两变量间互依关系3.回归系数有单位,相关系数无单位联系:1.方向一致:r和b正负号相同;2.假设检验等价:tr=tb;3.r=b根号(lxx/lyy)4.用回归解释相关决定系数R平方=lxy的平方/(lxxlxy)=ss回/ss总-=(ss总-ss剩)/ss总十.直线回归与相关的应用注意事项⑴要有实际意义;⑵不能任意“外延”;⑶绘制散点图十一.等级相关适用资料:⑴不服从双变量正态分布⑵总体分布类型未知⑶原始数据用等级表示等级相关系数rs——反映两变量间相关的密切程度与方向。注意:相同秩次较多时应校正rs