

- 126.40 KB
- 2022-08-29 发布


- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
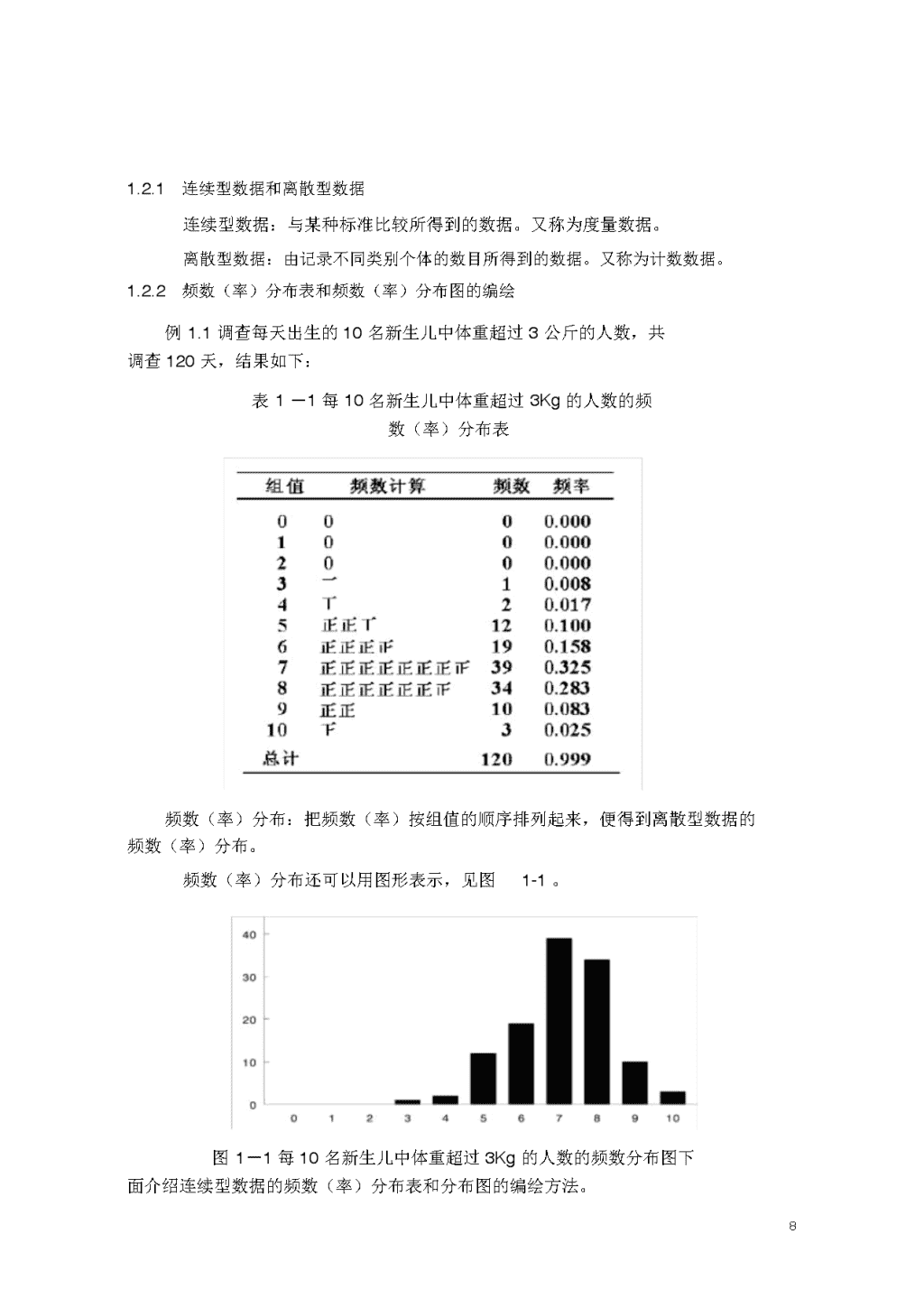
《生物统计学》教案第一章统计数据的收集和整理教学时间:2学时教学方法:课堂板书讲授教学目的:重点掌握样本特征数平均数、样本方差、标准差的概念和计算方法,掌握数据类型及频数(率)分布,了解众数、中位数、变异系数。讲授难点:样本方差、标准差的概念和计算方法1.1总体与样本1.1.1统计数据的不齐性1、变异性是自然界存在的客观规律。2、自然界如果没有变异,也就不需要统计学了。3、生物学研究的对象都是很大的群体,不可能研究全部对象,只能通过研究其中的一部分,来推断全部对象,于是引出以下概念。1.1.2总体与样本总体:研究的全部对象。个体:总体中的每个成员。样本:总体的一部分。样本含量:样本所包含的个体数目。1.1.3抽样抽样:从总体中获得样本的过程。随机抽样:总体中的每一个个体被抽中的机会都相同的一种抽样方法。放回式抽样:从总体中抽出一个个体,记下其特征后,放回原总体中,再做第二次抽样。非放回式抽样:从总体中抽出个体后,不再放回,即做第二次抽样。抽样的目的:从总体中获得一个有代表性的样本,以便通过样本推断总体。应注意的问题:①样本必须有代表性。②样本含量与可实施性之间的平衡。1.2数据类型及频数(率)分布7\n1.2.1连续型数据和离散型数据连续型数据:与某种标准比较所得到的数据。又称为度量数据。离散型数据:由记录不同类别个体的数目所得到的数据。又称为计数数据。1.2.2频数(率)分布表和频数(率)分布图的编绘例1.1调查每天出生的10名新生儿中体重超过3公斤的人数,共调查120天,结果如下:表1-1每10名新生儿中体重超过3Kg的人数的频数(率)分布表频数(率)分布:把频数(率)按组值的顺序排列起来,便得到离散型数据的频数(率)分布。频数(率)分布还可以用图形表示,见图1-1。图1-1每10名新生儿中体重超过3Kg的人数的频数分布图下面介绍连续型数据的频数(率)分布表和分布图的编绘方法。8\n例1.2表1-2列出了高粱“三尺三”提纯时所调查的100个数据。表1-2“三尺三”株高测量结果155153159155150159157159151152159158153153144156150157160150150150160156160155160151157155159161156141156145156153158161157149153153155162154152162155161159161156162151152154157162158155153151157156153147158155148163156163154158152163158154164155156158164148164154157165158166154154157167157159170158从上表中除可以看出最大值为170,最小值为141,以及平均高度大约在150-160之外,很难再看出什么规律出来。但将以上数据列成频数分布表以后,便可以清楚地看出数据的变化规律。表1-3“三尺三”株高频数(率)分布表频数(率)分布:把频数(率)按组界的顺序排列起来,便得到了连续型数据的频数(率)分布。从频数分布表中可见到的规律性:9\n1、植株矮的频数低,植株高的频数也低,植株中等高度的频数最高。2、频数分布基本是两侧对称的。3、植株平均高度在156-158厘米范围内。编制连续型数据频数(率)分布表的要点:1、求出极差R,R=maxx–minx,根据极差决定划分的组数,一般以10–15组为宜。2、根据极差和组数求出组距,按照组距划分组限。组限是按实验记录数据划分的每一组的上下限。3、确定组界,组界是每一组实际值的上下界。4、计算中值,中值是每一组组限的平均值。5、以唱票的方式把原始数据添入相应的组限内,统计出每组的频数并计算出相应的频率。连续型数据的频率分布同样可以用频数(率)分布图表示。下面是频数(率)分布的直方图。图1-2“三尺三”株高直方图横轴表明组界,纵轴标明频数(率),以每一组的组界为一边,相应的频数(率)为另一边,作成连续的矩形,构成直方图。10\n连续型数据的频数(率)分布还可以用多边形图表示。图1-3“三尺三”株高多边形图横轴为中值,纵轴为频数(率),标上各点,连接各点构成多边形图。第三种频数(率)图是累积频数图。首先编制出累积频数(率)表。再以横轴为中值,纵轴为频数(率)绘图。表1-4“三尺三”株高的累计频数分布表中值累积频数(率)中值累积频数(率)142115771145316086148716396151201669915443169100图1-4“三尺三”株高累计频数分布图11\n1.2.3研究频数(率)分布的意义1、可以描述数据的集中点,以平均值表示。2、可以描述数据变异的情况。3、可以描述数据分布的形状。4、可以显示数据中的不规则的情况。1.2.4频数(率)分布的不恒定性频数(率)分布是样本分布,由于不同次抽样的随机误差,造成样本间的波动。见下例。表1-5每10名行人中男性人数分布表样本1样本2男性人数频数男性人数频数01001211292631731842742554654062963071272084899391100100总计150总计1501.3样本的几个特征数样本特征数:描述样本分布特征的数字。如,平均数、标准差、偏斜度和峭度。1.3.1平均数12\n我们在这里使用的是算术平均数,以后一律简称为平均数。平均数以x表示,读作“x杠”或“杠x”。计算公式如下:nx1x2xni1xixnn(1.1)第二种平均数称为中位数,中位数是有序数列中点位置上的数。第三种平均数是众数,所谓众数是指具有最高频数的组值或中值。1.3.2平均数的计算方法1、非频数资料:非频数资料可以直接使用(1.1)式计算,不再举例。2、频数资料:计算离散型数据的频数资料时,可用下式:ki1fxixN(1.2)其中:x=组值,f=频数,N=总频数,k=组数以下计算例1.1的平均数。根据表1–1中的数据,列成下表。xffx000100200313428512606191147392738342729109010330总计12085013\n由公式(1.2)得xkfxi850i1N7.08120每10名新生儿中,平均有7名体重超过3公斤。计算连续型数据的频数资料时,与离散型数据类似。只要用连续型数据的中值代替离散型数据的组值即可,这里不再举例。1.3.3标准差可以用三个量来度量数据的离散程度。1、范围:又称为极差,它是一组数据的最大值与最小值的差。例如,以下5个数:96.4、96.6、97.2、97.4、97.8(ml)。它们的范围(R)R=97.8–96.4=1.4ml优点:简单。缺点:只利用了一组数据的两个极端值,不能客观地反映一组数据中每一个数据与平均数的偏离程度。为了解决范围所存在的缺点,需要求出一组数据中的每一个数与平均数的离差,然后再对该离差进行平均,以其平均数反映数据的离散程度。2、平均离差:先看下表离均差xxxx2xmlxxml2mlml96.6-0.480.480.230497.2+0.120.120.014496.4-0.680.680.462497.4+0.320.320.102497.8+0.720.720.5184x97.08和=0和=2.32和=1.3280为了求得离均差的平均数,首先要求离均差的和,从表中可见离均差的和为0。为了解决负数问题,求离均差绝对值的和,再以样本含量平均,从而得出平均14\n离差(MD)。MDxx2.320.464mln53、标准差:解决负数的问题除取绝对值外,另一个办法是取离均差的平方。所有离均差的平方相加称为离差平方和。按习惯做法,应当用样本含量n平均,但在这里不用n而用n–1平均,所得结果称为样本方差,记为s2。nxix22si1n1(1.3)上例中的方差s21.32800.332ml251方差的单位是原始数据的平方,为了使单位与原始数据相同,还必须对方差开方,开放后的方差称为标准差,记为s。s上例的标准差为n2xixi1n1(1.4)s0.3320.576ml抽样理论证明,三种对总体离散程度估计的方法中,标准差估计得最可靠,以后我们一律使用标准差。1.3.4标准差的计算方法1、非频数资料由1.4式计算标准差首先要计算出平均数,给计算带来一定的困难也影响结果的准确性。可将1.4式变为以下形式sn2nixixi21ni1n1(1.5)例1.3计算以下数据的标准差:26252824232527273021。解最好列成以下表格的形式计算15\nxx226676256252878424576235292562527729277293090021441和2566614将最后一行代入1.5式66142562s106.712.599如果对上表中的数字进行编码,则计算更为简便。取C=26。xx200-1124-24-39-111111416-525和-46216\n将上表中的最后一行代入1.5式中,得s=2.59。与未编码的结果一样。2、频数资料离散型数据可按下式计算k2ki1fxifx2iNsi1N1(1.6)其中,f=频数,x=组值,N=总频数,k=组数。对于连续型数据,只需将1.6式中的组值x,改为中值m。一般m的值都较大,需对m进行编码后再计算。对于频数资料的计算不再举例,同学可用例1.1和例1.2的数据为例进行练习。1.3.6变异系数标准差可以反映数据的离散程度,如果在两个样本之间进行比较,还要考虑标准差是在什么样的基础上进行的波动,即需要考虑两个样本平均数的大小。例如马和狗体重的标准差相同,那么谁更整齐呢?一定是马,因为马的体重远远大于狗。为此,引入变异系数(CV)这一概念。CVsx(1.7)例如,有以下两个样本:A=120±5.0;B=70±4.0,如果只看标准差前者没有后者整齐,但前者的变异是在120的基础上,而后者只是在70的基础上。它们的变异系数分别为:CV=0.042CV=0.057AB其结果还是A比B整齐。17