

- 166.50 KB
- 2022-08-29 发布


- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
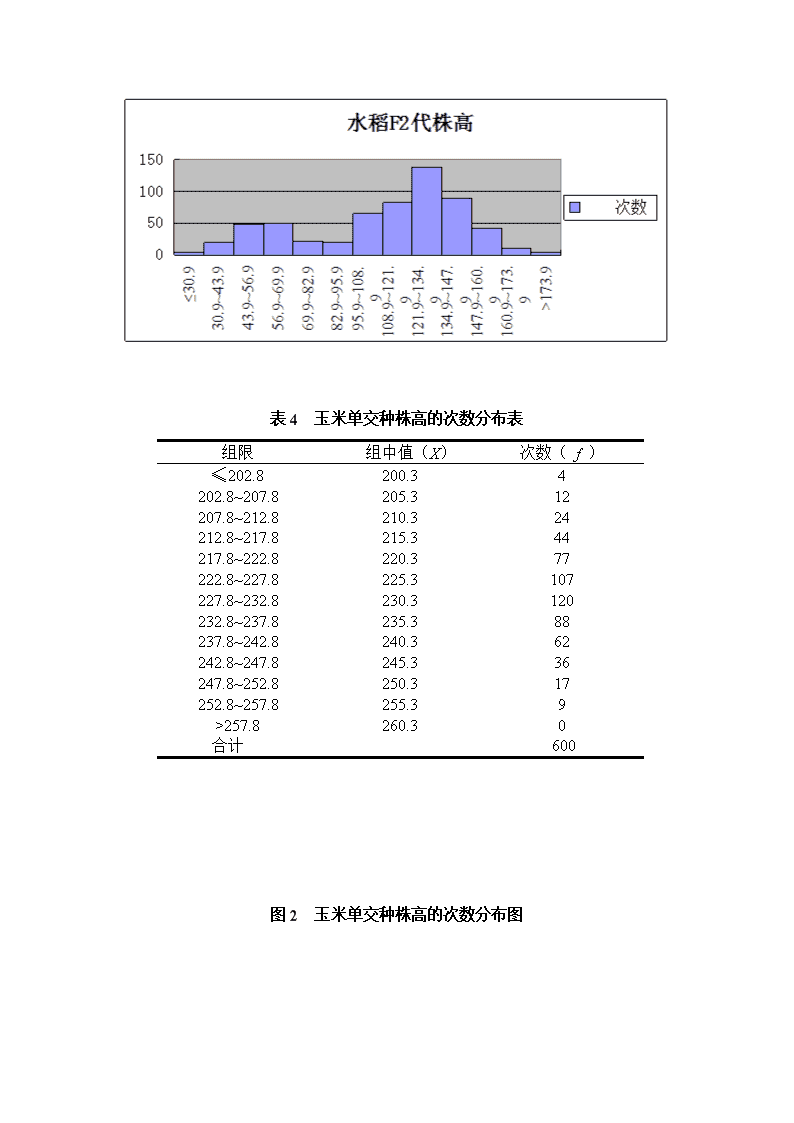
1、数据分析结果如下表:表1水稻F2代株高数据的基本特征数基本特征数计算结果平均数109.cm离均差平方和SS.226cm2方差S21202.cm2标准差S34.cm变异系数CV31.%最大值max177.6cm最小值min24.4cm极差R153.2cm样本大小n600峰值g2-0.偏斜度g1-0.分析:根据上表结果,在水稻F2代株高调查中,共抽取了600个样本。样本中最大值为177.6cm,最小值为24.4cm,极差为153.2cm;变异系数为31.%;其峰值为-0.,为一个小于0的值,说明其次数分布曲线比正态分布低,为低润峰;其偏斜度为-0.,小于0,说明该次数分布曲线不对称,且峰往右边偏。表2玉米单交种株高数据的基本特征数基本特征数计算结果平均数229.2075cm离均差平方和SS68065.63625cm2方差S2113.cm2标准差S10.cm变异系数CV4.%最大值max257.8cm最小值min200.3cm极差R57.5cm样本大小n600峰值g2-0.偏斜度g10.分析:根据上表结果,在玉米单交种株高调查中,共抽取了600个样本。样本中最大值为257.8cm,最小值为200.3cm,极差为57.5cm;变异系数为4.%;其峰值为-0.,小于0,说明其次数分布曲线比正态分布低,为低润峰;其偏斜度为0.,大于0,说明该次数分布曲线不对称,且峰往左边偏。\n2、比较两组数据变异程度的大小:水稻F2代株高:CV1=31.%玉米单交种株高:CV2=4.%水稻F2代株高的变异比玉米单交种株高的变异大。3、次数分布表与次数分布图表3水稻F2代株高的次数分布表组限组中值(X)次数(f)≤30.924.4530.9~43.937.42043.9~56.950.44956.9~69.963.45069.9~82.976.42282.9~95.989.42095.9~108.9102.466108.9~121.9115.483121.9~134.9128.4138134.9~147.9141.489147.9~160.9154.443160.9~173.9167.411>173.9180.44合计600图1水稻F2代株高的次数分布图\n表4玉米单交种株高的次数分布表组限组中值(X)次数(f)≤202.8200.34202.8~207.8205.312207.8~212.8210.324212.8~217.8215.344217.8~222.8220.377222.8~227.8225.3107227.8~232.8230.3120232.8~237.8235.388237.8~242.8240.362242.8~247.8245.336247.8~252.8250.317252.8~257.8255.39>257.8260.30合计600图2玉米单交种株高的次数分布图\n4、分析哪组数据更接近正态分布,为什么。水稻F2代株高的峰值为-0.,偏斜度为-0.;玉米单交种株高的峰值为-0.,偏斜度为0.;可看出玉米单交种株高的峰值与偏斜度均小于水稻F2代株高,因此玉米单交种的数据更接近正态分布。另从次数分布图亦可看出玉米单交种株高的分布接近于正态分布。5、正态分布适合性测验。表5水稻F2代株高的正态分布适合性测验次数Oi累计概率pi组概率pi理论数Ei卡方分量50.0.6.0.200.0.10.8.490.0.21.37.500.0.36.4.220.0.56.21.200.0.75.40.660.0.87.5.830.0.88.0.1380.0.77.47.890.0.59.15.430.0.39.0.110.0.22.6.40.19.12.600600199.df=13-1-2=1018.1.73808E-37199.分析:由于卡方分量为199.,大于\n18.。所以判断差异显著,可以认为资料不服从正态分布。表6玉米单交种株高的适合性测验次数Oi累计概率pi组概率pi理论数Ei卡方分量40.0.3.0.120.0.9.0.240.0.23.0.440.0.48.0.770.0.78.0.1070.0.104.0.1200.0.110.0.880.0.94.0.620.0.65.0.360.0.36.0.170.0.16.0.90.0.5.1.00.2.2.60016006.df=13-1-2=1018.0.6.分析:由于卡方分量为6.,小于18.。所以判断差异不显著,可以认为资料服从正态分布。