
- 231.00 KB
- 2022-08-29 发布


- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
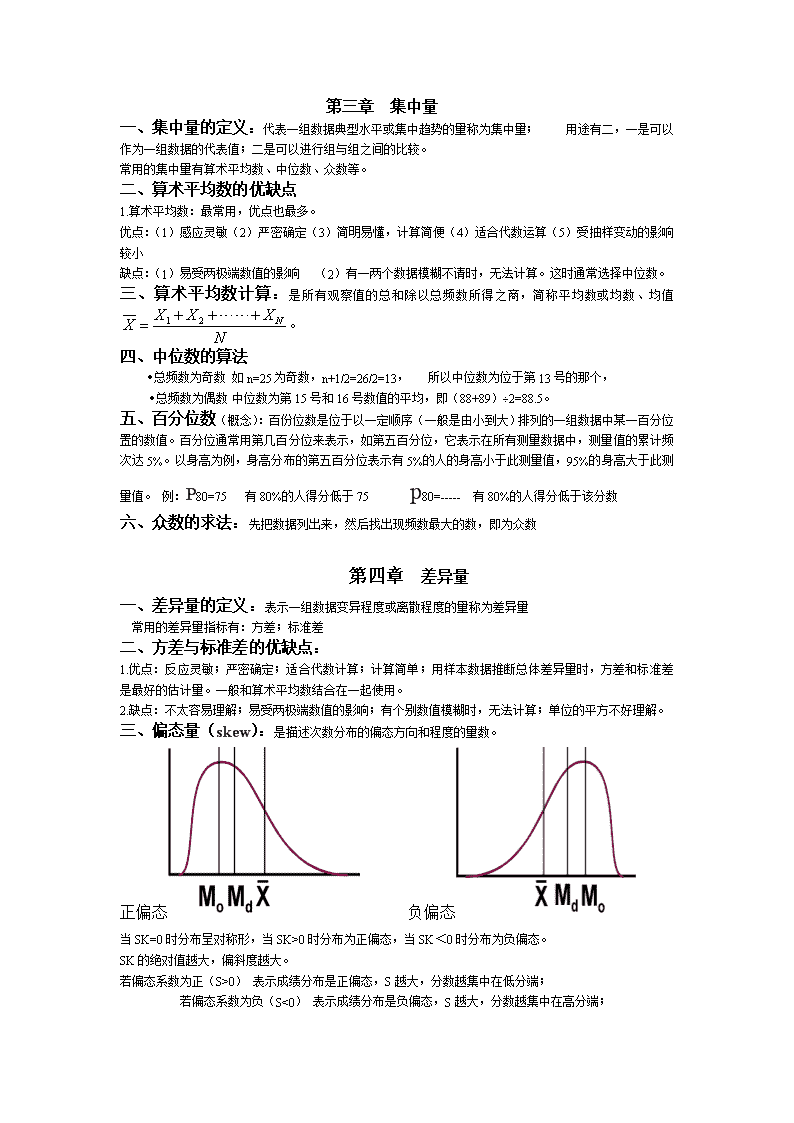
教育统计学第一章绪论一、什么是教育统计学:教育统计学是运用数理统计的原理和方法,研究教育问题的一门应用科学。主要任务是研究如何搜集、整理、分析由教育调查和教育试验所获得的数字资料,并以此为依据,进行科学推断,揭示教育现象所蕴含的客观规律。二、统计学的分类:描述统计推断统计理论统计应用统计描述统计:描述统计就是对已获得的数据进行整理、概括,显现其分布特征的统计方法.推断统计:根据样本所提供的信息,运用概率的理论进行分析、论证,在一定可靠程度上,对总体分布特征进行估计、推测,这种统计方法称为推断统计。(内容:参数估计和假设检验目的:对总体特征作出推断)三、具有以下三个特性的现象,称为随机现象第一,一次试验有多种可能结果,其所有可能结果是已知的;第二,试验之前不能预料哪一种结果会出现;第三,在相同的条件下可以重复试验。(延迟满足)四、样本容量(样本包含的个体数目大样本n>30小样本n<30五、参数和统计量参数(parameter)l描述总体特征的概括性数字度量,是研究者想要了解的总体的某种特征值。l所关心的参数主要有总体均值(m)、标准差(s)、总体比例(p)等l总体参数通常用希腊字母表示统计量(statistic)l用来描述样本特征的概括性数字度量,它是根据样本数据计算出来的一些量,是样本的函数l所关心的样本统计量有样本均值(`x)、样本标准差(s)、样本比例(p)等l样本统计量通常用小写英文字母表示l参数与统计量的符号系统第二章数据的处理一、名义、顺序、等距、比率①名义变量:是指一事物与其他事物在属性、类别上不同。1表示男,0表示女,但这里的1,0并不说明事物间差异的大小,只是分类的符号而已,即名称变量不说明事物之间差别的大小,作比较时,只能说明被比事物相同,还是不同顺序变量(ordinalvariable)。②顺序变量:是事物的某一属性的多少或大小按顺序排列起来的变量。如教师按能力大小或成绩高低排列等级:1,2,3,……,这一系列数据表明“大于”某某,即第1高于第2,第2高于第3……,而相邻两个等级的间隔是不等距的,即1与2和2与3之间并不等距。只有等级上的差别,是一种既无相等单位又无绝对零点的变量。③等距变量:在能力测验或知识测验中,或甲生得80分,乙生得60分,进行比较时我们可以说甲生比乙生多20分,但却不能以倍数来表示。这是因为这类数据只具有相等的单位,而没有绝对的零点。这类变量虽然有0分,但是这个0分是人为确定的。譬如某一个学生在数学测验中得了0分,我们并不能说他不没有一点数学能力或知识,这就像摄氏温度一样,0度并不意味着没有温度。④比率变量:比率变量是一种既有相等的单位,又有绝对零点的变量,又称等比变量,像人的身高、体重、距离、时间、教育投资、学校固定资产金额等均属于这种变量。\n第三章集中量一、集中量的定义:代表一组数据典型水平或集中趋势的量称为集中量;用途有二,一是可以作为一组数据的代表值;二是可以进行组与组之间的比较。常用的集中量有算术平均数、中位数、众数等。二、算术平均数的优缺点1.算术平均数:最常用,优点也最多。优点:(1)感应灵敏(2)严密确定(3)简明易懂,计算简便(4)适合代数运算(5)受抽样变动的影响较小缺点:(1)易受两极端数值的影响(2)有一两个数据模糊不请时,无法计算。这时通常选择中位数。三、算术平均数计算:是所有观察值的总和除以总频数所得之商,简称平均数或均数、均值。四、中位数的算法·总频数为奇数如n=25为奇数,n+1/2=26/2=13,所以中位数为位于第13号的那个,·总频数为偶数中位数为第15号和16号数值的平均,即(88+89)¸2=88.5。五、百分位数(概念):百份位数是位于以一定顺序(一般是由小到大)排列的一组数据中某一百分位置的数值。百分位通常用第几百分位来表示,如第五百分位,它表示在所有测量数据中,测量值的累计频次达5%。以身高为例,身高分布的第五百分位表示有5%的人的身高小于此测量值,95%的身高大于此测量值。例:P80=75有80%的人得分低于75p80=-----有80%的人得分低于该分数六、众数的求法:先把数据列出来,然后找出现频数最大的数,即为众数第四章差异量一、差异量的定义:表示一组数据变异程度或离散程度的量称为差异量常用的差异量指标有:方差;标准差二、方差与标准差的优缺点:1.优点:反应灵敏;严密确定;适合代数计算;计算简单;用样本数据推断总体差异量时,方差和标准差是最好的估计量。一般和算术平均数结合在一起使用。2.缺点:不太容易理解;易受两极端数值的影响;有个别数值模糊时,无法计算;单位的平方不好理解。三、偏态量(skew):是描述次数分布的偏态方向和程度的量数。正偏态负偏态当SK=0时分布呈对称形,当SK>0时分布为正偏态,当SK<0时分布为负偏态。SK的绝对值越大,偏斜度越大。若偏态系数为正(S>0)表示成绩分布是正偏态,S越大,分数越集中在低分端;若偏态系数为负(S<0)表示成绩分布是负偏态,S越大,分数越集中在高分端;\n考试难度大,学生得分普遍低,呈正偏态;考试难度小,学生得分普遍高,呈负偏态.n高狭峰:S较小,分数分布高窄,集中在平均数两侧。n低阔峰:S较大,分数分布低阔,散布较广。n正态峰:分布介于高峰态和低峰态之间。第四章参数估计一、推断统计:推断统计是研究如何利用样本数据来推断总体特征的统计方法。点估计含义:直接用样本统计量的值作为总体参数的估计值,样本均值就是总体均值m的一个估计量。如果样本均值`x=3,m的估计值点估计的理论依据1。对称分布的中位数与平均数重合,其样本平均数就是总体平均数和总体中位数的无偏估计量,也是一致估计量.2。根据中心极限定理,只要样本容量足够大,就可以近似地用正态分布去描述它.3。一般情况下,样本平均数是比样本中位数更有效的估计量,因为在大量样本中,样本平均数的平均误差比样本中位数的平均误差小.二、良好点估计量的条件无偏性一致性有效性区间估计:一定概率条件下样本统计量估计总体参数可能落入范围估计一个包含总体参数在内的区间,通常用区间的大小或者实际参数落在某个区间的概率两种方式表达区间估计的结果1.根据一个样本的观察值给出总体参数的估计范围2.给出总体参数落在这一区间的概率3.例如:总体均值落在50~70之间,置信度为95%1)置信区间定义:置信区间是指在特定的可靠性(即置信系数)要求下,估计总体参数所落的区间范围,亦即进行估计的全距。置信区间的涵义:以95%的可信区间为例,对于某一个区间而言,它包含总体均数的可能性为95%,而不包含总体均数的可能性仅为5%。因此在实际应用中,以这种方法估计总体均数犯错误的概率仅为5%。2)置信系数(置信度)定义:置信系数是指被估计的总体参数落在置信区间内的概率D,或以1-a表示。置信系数是用来说明置信区间可靠程度的概率,也是进行正确估计的概率。n符号:D(Degreeofreliability),或1-an别名:置信水平、置信系数、置信概率n常用值:D(1-a)=.95D(1-a)=.99三、显著性水平:统计学中把这种拒绝零假设的概率,显著性水平是统计推断时,可能犯错误的概率。a值和可靠度之间的关系是:两者之和为1。a值越大,可靠度就越低;a值越小,可靠度就越高。一个置信系数同时反映了在做出一个估计时所犯错误的小概率(),即可靠性为95%时,意味着犯错误的概率为5%;可靠性为99%时,意味着犯错误的概率为1%。显著性检验的一般步骤:1.提出假设2.选择检验统计量并计算其值3.确定检验形式4.统计决断双侧Z检验统计决断规则|Z|与临界值的比较P值检验结果|Z|<1.96P>0.05不显著1.96£|Z|<2.580.010.05不显著1.65£|Z|<2.330.010.05n不显著nt(df)0.05£|t|
-
 关注微信公众号售出明细实时看
关注微信公众号售出明细实时看