

- 2.09 MB
- 2022-08-30 发布
- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
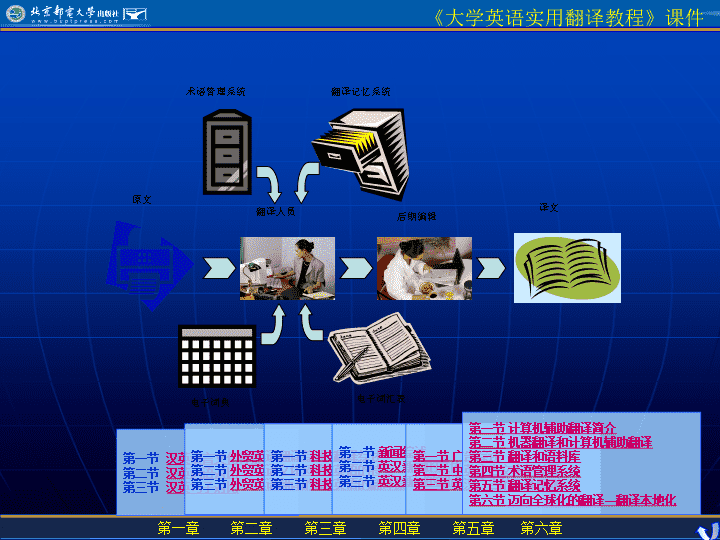
计算机辅助翻译\n计算机辅助翻译现阶段翻译的问题:完全的机器翻译还满足不了信息沟通、文化交流的需要,完全的人工翻译速度太慢解决方案:计算机辅助翻译优点:帮助译者优质、高效地完成翻译工作。\n原文翻译人员译文后期编辑术语管理系统翻译记忆系统电子词汇表电子词典\n第三节翻译和语料库语料库通常指为语言研究收集的、用电子形式保存的语言材料,由自然出现的书面语或口语的样本汇集而成,用来代表特定的语言或语言变体。目前,语料库已经成为语言学理论研究、应用研究和语言工程不可缺少的基础资源。\n3.1.语料库类型特殊语料库普通语料库比较语料库平行语料库学习者语料库教学语料库历史语料库\n语料语种分类单语语料库双语语料库多语语料库\n3.2.语料库对翻译技术的影响术语研究词典编纂搭配词典编纂翻译辅助和翻译软件研发\n3.3.语料分析工具借助电子文集的附加或者各种标识对复杂的语言现象进行大规模数据搜集。语言学研究中,语料库主要用来为统计语言模型提供语言特征信息和概率数据,在语言研究的其他领域,多使用语料检索和频率统计结果语料库分析工具可以提供一系列服务\n3.3.语料分析工具语料词频分析DISTRIBWORD/PHRASETOKENSREG1PERMILINREG1[100,000,000WORDS]1CONCERNED14667146.672CONSIDERABLE946794.673CONSTANT439443.944CONTEMPORARY424542.455CONSERVATIVE389638.966CONVENTIONAL388638.867CONFIDENT315531.558CONSISTENT307530.759CONSCIOUS297929.7910CONSTITUTIONAL293429.3499CONTRACEPTIVE920.92100CONJUGAL860.86(来源:BritishNationalCorpus)\n3.3.1字频、词频列表语料分析工具能对具体的字词频率进行统计比较,对字词的差别进行计量分析。使用者可以通过这些分析工具来检索语料库中一共有多少个没有重复出现的词——类符、每个词出现的频率是多少——形符。\n词频表操作方式1:不同顺序来排列2:根据词在语料库中的出现的顺序排列3:根据字母顺序排列4:根据出现频率的次数排列。这些顺序可以是从小到大排列,也可以从大到小排列,极为灵活。\n其他功能除了词频统计,计算机分析工具还可以帮助我们统计类符形符比计算出语料库中的句子和段落的总数计算出语料库中词、句、段的平均长度,从而帮助译者确定语料库中所收文章的文体特点。\n3.3.2.语料检索语料检索软件——相关集列系统语料检索软件主要应用于语言学习、文献分析、语料库语言学、术语学和词汇学等方面。\n3.3.2.1.单语检索1:键入需要查询的词或词组2:检索软件在相关文档中显示出它们所在的位置。词节(关键词)——被检索词检索行——显示这些关键词的句行在检索过程中,被检索词一般会在屏幕上高亮显示,并且置中。在计算机辅助翻译中,这种检索显示称为“上下文关键词”,经常用KWIC来代替软件:WordSmith、MConcord等\n通配符检索通配符——一个可以在检索时代替其他字符的符号。例如“?”、“*”等符号,一般来说,用“?”代替任何一个字符,用“*”代替任何字符或者字符串。例如:输入“ho?se”来进行搜索,可以产生“house”和“horse”等多个词。\n\n3.3.2.2.双语检索语料库在翻译中的运用主要通过双语检索途径实现。如果要使用双语检索功能,就需要建立一个双语平行语料库来支持它,最好对语料库里的文本预先进行排列。文本自动对齐是建立双语语料库的关键技术。自动对齐工具最基本的处理方法是:把原文的第一个句子和译文的第一个句子加以排列,原文的第二句与译文的第二句加以排列,以此类推。\n自动对齐常见问题举例英文句子的句尾符号是“.”很多词的词尾也会出现“.”号。常见的有“Mr.”、“Mrs.”等词汉语的问题——汉语语句简短、干练,往往一个英语句子,会被翻译成两个或者更多的汉语句子。这些都不可避免地为原文和译文自动对齐带来困难。\n图6使用WordCruncher创建的英汉平行语料库\n4.1.术语管理系统的作用能够帮助译者解决很多翻译问题,可以帮助存储、检索并且更新术语库,给译者提供一个完整的术语规范,从而保证译文中术语的一致性和翻译的质量。用户一次性建立一个或多个标准术语列表(表中包括术语原文和译文)在使用术语管理系统进行翻译时,打开术语管理工具中相应的术语列表,系统就会自动识别出当前句子中有哪些词是已定义的术语,并给出标准的术语译文,省掉了校对的麻烦。\n4.2.创建新的术语库术语库多由政府、公司、语言学协会等组织来创建。最知名的术语库是EURODICAUTUM,——12种语言,91个领域。通讯领域内最重要的术语库是“ACRoTERMITE”,包含阿拉伯语、汉语、英语、法语、俄语和西班牙语等6种语言。用在本地化等行业的商用术语库Multiterm、TranslationStar、TranslationManager和SDLX等。\n4.3.术语检索术语经过存储之后,使用者就需要检索这些经过存储的术语信息。一些术语管理系统允许通配符和截词检索。搜索引擎最常用的通配符有星号(*)和问号(?)等,(*)表示替代若干字母,(?)表示替代一个字母。通配符可以分为“词间通配符”和“全词通配符”两种。截词检索使用“词间通配符”,用截断词的一个局部进行检索。截词有很多种方式,大致可以分为有限截词、无限截词和中间截词\n术语模糊匹配基本思路——找出输入的句子和实例中共同的单词,保留相同的词,只对不同的词进行翻译。如:美国国务卿奥尔布赖特今天起访问韩国。美国国务卿鲍威尔明起访问日本。\n术语匹配\n4.4.术语自动提取及自动识别术语提取——用现有的词库对语料切分,通过语法规则和语料特征进行过滤,找出备选术语。术语识别——利用当前术语在语料库中的可信度,并结合上下文特征确认备选术语中的术语。\n4.4.2.自动提取和识别术语的必要性科技信息的飞速发展大量的科技文献大批新的术语为了尽快规范和统一术语,以免造成更多歧义,我们需要随时收集并解释这些新出现的术语,不仅降低了翻译中的重复劳动,而且可以保持翻译文档术语的一致性。\n4.4.3.术语自动识别和提取模式在语料库识别的初阶段,会进行手工分析,来识别语料库中的术语构成,并对所有可能的组合进行列表,然后输入这些组合来提取术语。常见的术语识别模式有:定位识别方式组合识别方式通过高频词识别方式句法识别方式等。\n4.4.3.术语自动识别\n4.4.3.术语自动提取术语提取一般有两种方式:语言学方式和统计方式。语言学方式——使用语言学方式的术语提取工具可以对特定的词性进行识别。统计模式——利用术语提取工具找出重复词项。\n4.5.1.术语管理系统的优点I.保持术语的一致性,使文档译文整齐化一,保证译文质量,维护商业形象;II.具有便捷灵活的存储和检索方式,便于使用和更新;III.有利于资源共享。IV.帮助译者了解行业知识和专业术语,提高译者专业水平和翻译能力。\n4.5.2.术语管理系统的缺点术语管理系统并非完全智能管理,很多情况下需要人工编辑。很多计算机应用程序只支持单字节,这难免会给使用双字节编码模式的语言(例如包括汉语在内的亚洲各国语言)共享术语库带来困难\n第五节翻译记忆系统是一种通过计算机软件来实现的专业翻译解决方案。把经过翻译的译文和原文一块存储在记忆库里,以备重复使用。\n第五节翻译记忆系统应用范围大多集中于一些特定的专业领域,例如,医药、经济、军事、航天、计算机、通讯等领域。原因:专业翻译领域涉及的翻译资料数量巨大,但是范围较窄,重复率极高。\n1:交互形式:译者从屏幕上的待译文本中逐个选择翻译单元,每次选择之后,程序就会在记忆库中自动搜索相同或相近的内容,并在另外一个窗口中生成可能的翻译。2:自动形式:程序自动处理整个源语文本,并把在记忆库中找到的翻译插入目标语文本中。\n5.1.翻译记忆系统的基本单位以“翻译单元”为数据单位,对源语言和目标语言的句段建立对应链接关系。使之构成翻译单元。\n5.2.记忆系统中匹配模式完全匹配模糊匹配术语匹配复杂匹配\n5.2.1.完全匹配完全匹配指的是需要翻译的内容和记忆库里存储的译文在语言上和形式上都达到100%相同。在完全匹配的状况下,记忆库里的句段和正在翻译的句段在拼写、单复数、发音甚至形式(大小写、黑体、斜体等)等方面都完全相同:\n完全匹配人工示意图\n5.2.2.模糊匹配正在翻译的句段与记忆库中已有的句段类似,但不完全相同。\n5.2.3.术语匹配作用:如果找不到完全或者模糊匹配,至少可以在术语库中找到单个的术语,达到术语在整个翻译过程中的统一。\n5.2.4.复杂匹配翻译记忆系统中的相似性尺度可能基于单个词或者整个句子,或者两者皆有。有的记忆系统比较复杂,能够把语言学中词性的曲折变化、同义词甚至语法变化等方式结合起来,构建翻译匹配模式。例如以下几个句子:1.Whenyoufinishtranslatingthesentence,click"ok"toinputitintothetranslationsystem.2.Whenyoufinishtranslatingtheword,click"ok"toinputitintotheterminologysystem.3.Click"ok"toinputthetranslatedsentenceintothetranslationmemorywhenyoufinishit.4.Whenyoufinishattachingthedocument,click"continuetothemessage"andsendthemail.\n5.3.翻译记忆系统的实现途径比较并提取记忆库单元新原始文本新目标文本创建新文本储存\n5.3.1.建立翻译记忆库两种建立翻译记忆库的方式——一是交互翻译,二是后期排列。交互翻译:使用翻译记忆库进行工作时,把翻译好的单元及时储存到记忆库中,经储存的翻译单元就马上成为新的翻译记忆库的一部分。如果下一次再遇到相同或者相似的翻译单元,记忆库就会自动搜索,并提出翻译建议,如果完全匹配,就可以直接点击接受,如果模糊匹配,则需要稍加编辑之后再选取,这就是交互翻译的方法。后期排列:把现有的翻译单元进行排列,使原文和译文形成对应关系,并存储到记忆库中,以供再次利用。\n5.4.使用翻译记忆系统的优缺点分析5.4.1.主要优势I.重复利用现成的翻译单元,大大缩短翻译时间和译者的劳动量。II.有效地节省翻译成本。III.有利于保持整个文档的统一,提高译文精确度。IV.大部分翻译记忆工具和术语管理系统集成使用,而术语库可以自动显示原文关键术语,能够更好地保证术语一致性。V.由于翻译记忆库的记忆功能,提高重复率,方便译者使用。VI.翻译记忆库具有用户友好特征,便于操作。VII.能够极大地减缓翻译的复杂性,简化项目管理和团队翻译。\n5.4.2.主要缺点I.译者需要在翻译之前就对此掌握,在刚开始翻译时,很可能不但无法提高,反而会降低翻译效率。II.为了最好地利用翻译记忆系统,用户一般会按照句子顺序来排列翻译单位,难免会有翻译的痕迹,降低译文的可读性。III.由于记忆涉及到不同语言之间的问题,所以会带来一些技术问题。IV.翻译记忆系统重复利用已有资源的优势也直接导致了它可能带来的危险。在一些情况下,很可能会出现对“不良译文”的重复使用,从而导致恶性循环,产生更多的低质量译文。V.翻译记忆对一些特殊领域的文本自然有极大的帮助,但是,对于文学文本,作用并不是很大。VI.大部分翻译记忆工具并不显示文档格式,所以很难看出来文档出现的最终形式。VII.翻译记忆对于相对简单的文本处理起来比较有效,但是,它只能处理语言片段比较简单的文本,无法分析整体语篇。\n第六节——本地化翻译本地化——将一个产品按特定国家/地区或语言市场的需要进行加工,使之满足特定市场上的用户对语言和文化的特殊要求的软件生产活动。主要功能:将产品或软件针对特定国际语言和文化进行加工,消除双方在语言和文化方面的障碍,使产品适应目标国家的语言和文化标准,符合特定区域市场。\n本地化的过程考虑因素目标区域市场的语言、文化、习俗和特性。包括宗教、地理、气候、货币形式、法规、命名、度量衡系统、软件的书写系统(输入法)、键盘排列、字体、日期、时间、书信格式、标点符号和货币格式等都需要进行适当地调整和适应,例如,汉语和英语的姓名格式\n本地化翻译一般来说,本地化活动包括以下几类内容:1.项目管理2.软件的翻译和工程3.在线帮助或者网络内容的翻译、工程和测试4.文献的翻译和DTP桌面出版服务5.多媒体或计算机培训的翻译和集成6.本地化软件或网络应用的功能测试\n本地化翻译与传统翻译不同传统的翻译活动中,翻译只是单纯地实现翻译内容由一种语言到另外一种语言的转换本地化翻译除了传统的翻译功能,它还包括多语言项目管理、软件和在线帮助工程及测试、把翻译文档转换为其他格式、翻译记忆排列和管理、多语言产品支持以及翻译战略咨询等。\n本地化翻译的要求言简意赅,不罗嗦赘言忠实、准确地传达原文信息符合目标语表达习惯、语法和语言逻辑尽量采取归化的策略,适时调整原文信息保持原文和译文文体的一致性在整篇文档中保持术语一致性和专业性充分了解目标语市场文化,处理文化冲突