

- 2.10 MB
- 2022-09-01 发布


- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
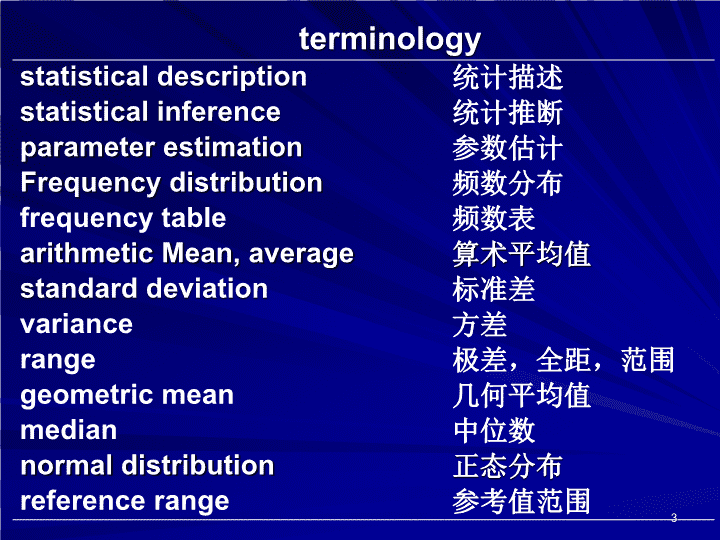
第三篇医学统计学方法StatisticalMethodsinMedicine1\n第九章 数值变量资料的统计分析第一节数值型资料的统计描述第二节正态分布和参考值范围的估计第三节数值型资料的统计推断第四节t检验和u检验第五节方差分析2\nterminologystatisticaldescription统计描述statisticalinference统计推断parameterestimation参数估计Frequencydistribution频数分布frequencytable频数表arithmeticMean,average算术平均值standarddeviation标准差variance方差range极差,全距,范围geometricmean几何平均值median中位数normaldistribution正态分布referencerange参考值范围3\n统计分析包括统计描述和统计推断两大部分。统计描述(statisticaldescription)是用统计指标、统计表和统计图描述资料的分析规律及其数量特征;统计推断(statisticalinference)包括总体参数估计和假设检验两个内容。参数估计:是用样本统计量估计总体参数所在范围。假设检验:是利用样本的实际资料来检验事先对总体某些数量特征所作的假设是否成立。4\n第一节数值型变量资料的统计描述例9.1 2002年某市150名20~29岁正常男子的尿酸浓度(μmol/L),资料见表9-1。如何进行统计描述?5\n362.6359.7285.9300.2333.6334.0288.8338.5341.9344.63375298.3364.2367.1338.1316.9332.7324.0282.6369.8398.7338.7308.9392.1368.7352.6378.2346.1278.6318.3323.2322.6382.1322.6309.6352.0372.5399.8335.6341.1371.0355.9362.7368.1332.4405.6328.8358.8405.9362.7316.3338.7402.6379.4329.6354.6331.4349.6419.5324.6329.8357.8312.0313.6338.7328.6291.3329.7361.8392.4414.9319.7327.6395.8358.9289.4366.2387.4298.4408.7389.8362.5354.9352.7316.6348.9348.7401.6334.6308.9367.0345.6401.6357.1304.6338.5388.2355.8329.4321.1320.4313.5339.8409.4387.4378.5392.0352.7376.2388.4344.6308.6347.0428.7369.1311.4376.3349.4289.2366.8371.0387.5413.6348.7392.7401.0313.6366.8387.2319.7329.4357.5348.5346.8406.6357.6338.7341.6349.8289.4366.2357.5298.4336.8387.5342.3366.7387.6332.7324.0表9-1 2002年某市150名20~29岁正常男子的尿酸浓度(μmol/L)6\n统计描述的内容:一、制频数(分布)表(表9-2)和频数分布图(图9-1)频数表的用途(1)揭示资料的分布特征和分布类型(2)便于发现某些特大或特小的可疑值(3)便于进一步计算统计指标和统计分析处理二、计算统计指标(1)计算平均值—代表一组资料的平均水平;(2)计算标准差---反映资料的离散程度。三、绘制统计表和统计图7\n一、编制频数分布表:制表步骤:(1)求极差或全距(range):R=Xmax-Xmin本例,R=428.7-278.6=150.1(μmol/L)。(2)决定组数、组段数和划分组距(classinterval):根据样本含量的多少确定组数,一般设8~15组。组段数=取整(极差/组数)。本例:组段数=取整(150.1/10)=15.0115划分组距:每组段的起点和终点分别称为下界和上界。组距:本组内的上界和下界之差。组段的划分270~285~300~315~330~345~360~375~390~405~420~43512345678910118\n(3)列频数表:按上述组段序列制成表的形式,采用划记法或计算机将原始数据汇总,得出各组段中所包含的观察例数,即为频数,如表9-2的第(2)栏。将各组段及其相应的频数列成表格,即为频数表(frequencytable),如表9-2。所绘的图形见图9-1。表9-2 2002年某市150名20~29岁正常男子的尿酸浓度的频数分布尿酸浓度(μmol/L)频数频率(%)270~21.33285~96.00300~117.33315~2214.67330~2416.00345~2718.00360~2013.33375~1510.00390~117.33405~85.33420~43510.67合计150100.009\n资料的分布类型:对称分布或正态分布;2.偏态分布:高峰在左侧或右侧;3.不规则分布:分布很散,无明显高峰10\n二、计算平均值—代表平均资料的平均水平1.平均值的种类:(一)算术均值(arithmeticmean,average):常用表示样本均值,希腊字母μ表示总体均值。适用于对称分布的数值型变量资料。其计算方法有:①直接法:χi(I=1,2,…,n)为第i个观察对象的观察值②加权法:χi为第i组的组中值,fi为第i组的例数:11\n表9-2 分组资料加权法计算平均值及标准差用表尿酸浓度(μmol/L)组中值(xi)频数(fi)fi×xifi×xi2270~277.52555.0154012.5285~292.592632.5770006.3300~307.5113382.51040119.0315~322.5227095.02288138.0330~337.5248100.02733750.0345~352.5279517.53354919.0360~367.5207350.02701125.0375~382.5155737.52194594.0390~397.5114372.51738069.0405~412.583300.01361250.0420~435427.51427.5182756.3合计15052470.018518738.012\n(二)几何均值(geometricmean,G)适用条件:等比级数资料.原始观察值呈偏态分布、但数据经过对数变换后呈正态分布或近似正态分布的资料。如医学实践中某些疾病的潜伏期、抗体滴度、平均效价等。其计算方法有:①直接法:χi为第i个观察对象的观察值②加权法:χi为第i组的组中值(或观察值),fi为第i组例数:13\n抗体滴度(i)人数fi滴度倒数Xilg10(Xi)fi×lg10(Xi)(1)(2)(3)(4)(5)=(2)×(4)1:2.532.50.39791.19371:5.075.00.69904.89301:10.01410.01.000014.00001:20.0620.01.30107.80621:40.0440.01.60216.4084合计3434.3013表9-4某地34名儿童接种麻疹疫苗后血清血凝抑制抗体滴度血清血凝抑制抗体的几何平均滴度为1:10.206。X=(2.5×3+5.0×7+10.0×14+20.0×6+40.0×4)/34=13.6(算术平均滴度为1:13.6)14\n(三)中位数(median,M):将观察值按大小排序后,位次居中的观察值。M=X(P=50%)在全部观察值中小于M的观察值个数与大于M的观察值个数相等。由于M不受个别特小或特大观察值的影响,适用于分布不规则或分散度很高的资料.3个观察值:1,3,5.M=3;4个观察值:1,3,5,7.M=4.①直接法:设n为观察值的个数,有公式(9-5)及(9-6)②频数表法:χi为第i组的组中值(或观察值),fi为第i组例数:L:中位数组段下限值,ΣfL:小于L的累计频数,i:中位数组距.15\n尿铅值(mmol/L)人数f累计频数Σf累计频率(%)(1)(2)(3)(4)=(3)/n0~27278.7725~548126.3050~9517657.1475~5523175.00100~3927087.66125~2129194.48150~1230398.38175~5308100.00合计308表9-5308名6岁以下儿童尿铅值的频数分布(中位数计算)L:中位数组段下限值,ΣfL:小于L的累计频数,i:中位数组距,f50%:中位数组频数.L=50,ΣfL=81,i=25f50%=9516\n三、计算标准差---反映资料的离散程度。数值变量数据的频数分布有集中趋势和离散程度两个主要特征,只有两者相结合,才能全面地认识事物。反映资料的离散程度的统计量(统计指标)有:(一)全距(range)或极差:R=Xmax-Xmin全距是一组观察值中最大值与最小值之差。(二)四分位数间距(quartileinterval):Q=X75%—X25%,Q包括了全部观察值中间的一半.(三)方差(variance)和标准差(standarddeviation)17\n例 有3组同龄男孩的体重(㎏)测量值如下,其平均体重都是30(㎏),试分析其离散程度。分组观察值(㎏)全距RQS甲组262830323430843.16乙组2427303336301264.74丙组262930313430822.92丙组*****乙组*****甲组*****体重232425262728293031323334353637(㎏)18\n标准差的简化计算方法:数学上可证明:故标准差的计算公式又可写成:直接法:X为观察值加权法:Xi为组中值表9-3尿酸浓度(μmol/L)分组资料加权法计算平均数及标准差用表n=∑fi=150∑(fi×xi)=52470.0∑(fi×xi2)=18518738.019\n标准差的应用:(1)表示观察值的变异程度(离散程度):在两组(或几组)资料均数相近、度量单位相同的条件下,标准差大,表示观察值的变异度大,即各观察值离均数较远,均数的代表性较差。(2)结合均数描述正态分布的特征和估计医学参考值范围。(3)结合样本含量n计算标准误。20\n四分位数间距的计算(interquartilerange,Q):中位数计算公式:25%位数计算公式:75%位数计算公式尿铅值(mmol/L)人数f累计频数Σf累计频率(%)(1)(2)(3)(4)=(3)/n0~27278.7725~548126.3050~9517657.1475~5523175.00100~3927087.66125~2129194.48150~1230398.38175~5308100.00合计30821\n四分位数间距(interquartilerange,Q)计算公式:Q=X75%–X25%X0%X25%X50%X75%X100%|Q|048.1569.21100.0175~X1…Xn22\n描述性统计量归纳反映资料的集中趋势的指标反映资料的离散情况指标适用的资料类型1.算术平均数方差及标准差对称分布,特别是正态或近似正态分布资料。2.几何平均数几何标准差适用于对数正态或近似对数正态分布资料3.中位数四分位数间距或百分位数分布不规则的资料,分散程度大的资料23\n变异系数(coefficientofvariation,CV):若比较度量单位不同或均数相差悬殊的两组(或几组)观察值的变异度,则需用变异系数为相互比较的指标。不属于描述性统计指标,是一个比较用的统计指标。从变异系数比较,体重的变异程度大于身高的变异程度。变异系数的特点:描述的是相对离散程度,没有单位。适用于:(1)比较单位不同的多组资料的变异度。(2)比较均数相差悬殊的多组资料的变异度。例9-10某地25岁男子100人的调查结果如下:问题:哪一个指标的变异度大些?24\n第二节正态分布和医学参考值范围一、正态分布(normaldistribution)25\n表9-2 尿酸浓度的频数分布尿酸浓度(μmol/L)频数270~2285~9300~11315~22330~24345~27360~20375~15390~11405~8420~4351合计150图9-2 频数分布逐渐向正态分布接近26\n(一)正态分布的图形可以设想,如果观察例数逐渐增多,组段数也不断增多,就会形成一条光滑曲线[图9-2(3)]。称为正态分布曲线。这条正态分布曲线的特点为:①高峰位于中央均数所在处、两侧逐渐降低;②左右对称;③曲线在无穷远处与横轴相交。把服从正态分布的变量表示为:X~N(μ,σ2)正态分布曲线由两个参数确定:①平均数μ,称位置参数,决定平均数所在的位置;②方差σ2,称形状参数,决定曲线的高低宽窄。27\n服从正态分布的变量X的概率密度函数f(X)为式中,μ为总体均数;σ为总体标准差;π=3.14159为圆周率;e为自然对数的底(e≈2.71828),X为变量。表示为:u~N(0,1),即平均值为0、方差为1的正态分布。为实际应用方便,将一般正态分布转换为标准正态分布。转换公式为:u=(X-μ)/σ,u称为标准正态变量。服从标准正态分布的变量u的概率密度函数f(u)为28\nA.正态分布B.标准正态分布图9-3正态分布与标准正态分布的面积与纵高按式(9-16),根据X的不同取值,绘出正态分布(normaldistribution)的图形(图9-3A)。按式(9-16),根据u的不同取值,绘出标准正态分布(standardnormaldistribution)的图形(图9-3B)。Xu29\n图9-4正态曲线与标准正态曲线的面积分布二、正态曲线下面积的分布规律:用积分法求得。表9-6正态分布和标准正态分布曲线下面积(概率)分布规律对照正态分布标准正态分布面积(概率)%左侧界值~右侧界值左侧界值~右侧界值中间部份两侧尾部和μ-1.0σ~μ+1.0σ-1.0~+1.068.2731.73μ-1.96σ~μ+1.96σ-1.96~+1.9695.005.00μ-2.58σ~μ+2.58σ-2.58~+2.5899.001.0030\n为了省去计算的麻烦,编制成了“标准正态分布曲线下的面积”(表9-8)。表中列出了左侧概率:Φ(-∞,-u);右侧概率:Φ(u,+∞)=Φ(-∞,-u),Φ(-∞,u)=1-Φ(-∞,-u)通过查表可求出正态曲线下某区间的面积,进而估计该区间观察例数占总例数的百分数或变量值落在该区间的概率。查表时应注意:①当μ,σ已知时,先将观察值X变换为u值[u=(X-μ)/σ],再查表;②当μ,σ未知、但n足够大时,可以用样本均数和样本标准差s分别代替μ和σ,进行u变换[u=(X-)/s]求得u的估计值后再查表;③曲线下对称于0的区间面积相等,如Φ(-∞,-1.96)=Φ(1.96,∞)④曲线下横轴上的总面积为100%或1。.31\n三、医学参考值范围的估计㈠参考值范围(referencerange)的意义参考值是指正常人体或动物的各种生理常数,正常人体液和排泄物中某种生理生化指标或某种元素的含量,以及人体对各种试验的正常反应值等。由于存在个体变异,各种数据不仅因人而异,而且同一个人还会随机体内外环境的改变而改变,因而需要确定其波动的范围,即医学参考值范围,亦称医学正常值范围。32\n制订医学参考值范围时须注意:①从同质总体中随机抽样。根据研究目的确定同质总体的标准。排除患有影响所研究指标的疾病和有关因素的同质人群。②需要有一定的样本含量。n≥100例。③控制测量误差。④判断是否需要分组确定参考值范围。如不同性别,不同年龄组,甚至不同民族。⑤确定是取单侧还是取双侧参考值。⑥确定适当的百分数范围。80%,90%,95%,99%。范围过窄,即诊断标准过严,会增加漏诊;范围过宽,即诊断标准过松,会增加误诊;⑦根据资料分布类型选择统计学方法估计参考值范围。33\n表9-7三种参考值估计方法的适用对象和95%参考值范围的计算资料类型统计方法双侧界限值单侧上界值单侧下界值正态或近似正态分布正态分布法对数正态或近似对数正态分布对数正态分布法不规则分布百分位数法例9-11,表9-2 2002年某市150名20~29岁正常男子的尿酸浓度资料。X=350.24(μmol/L),S=32.97(μmol/L).用正态分布法双侧95%的参考值范围的上下界限值为:下界:350.24-1.96×32.97=285.62(μmol/L),上界:350.24+1.96×32.97=414.86(μmol/L)即20~29岁男性尿酸浓度95%参考值范围:285.62~414.86(μmol/L)34\n例9-12,例9-7表9-5,308名6岁以下儿童尿铅值资料。用百分位数法计算单侧95%参考值范围的上界值。即X95%尿铅值(mmol/L)人数f累计频数Σf累计频率(%)(1)(2)(3)(4)=(3)/n0~27278.7725~548126.3050~9517657.1475~5523175.00100~3927087.66125~2129194.48150~1230398.38175~5308100.00合计308L=150:95%组段下限值ΣfL=291:小于L的累计频数i=25:95%组的组距f95%:=12:95%组频数故6岁以下儿童尿铅值单侧95%参考值范围为:<153.33(mmol/L)35\n本章小节资料类型描述性统计量95%参考值范围的计算对称分布,特别是正态或近似正态分布资料算术平均数方差及标准差正态分布法:根据正态分布规律双侧:单侧上界:单侧下界:适用于对数正态或近似对数正态分布资料几何平均数几何标准差对数正态分布法:双侧:单侧上界:单侧下界:分布不规则的资料,分散程度大的资料中位数四分位数间距或百分位数百分位数法:按排序的位置清点位次双侧:X2.5%~X97.5%单侧上界:X95.0%单侧下界:X5.0%36\nTheend37\n第九章第一讲《练习题》实习九数值变量资料的统计分析(1)pp.379-382[内容](一)选择题:1,2,3,9,10。(二)思考题:1,2,6。(三)应用题:1,2,3。38\nu.00.01.02.03.04.05.06.07.08.09-3.0.0013.0013.0013.0012.0012.0011.0011.0011.0010.0010-2.9.0019.0018.0018.0017.0016.0016.0015.0015.0014.0014-2.8.0026.0025.0024.0023.0023.0022.0021.0021.0020.0019-2.7.0035.0034.0033.0032.0031.0030.0029.0028.0027.0026-2.6.0047.0045.0144.0043.0041.0040.0039.0038.0037.0036-2.5.0062.0060.0059.0057.0055.0054.0052.0051.0049.0048-2.4.0082.0080.0078.0075.0073.0071.0069.0068.0066.0064-2.3.0107.0104.0102.0099.0096.0094.0091.0089.0087.0084-2.2.0139.0136.0132.0129.0125.0122.0119.0116.0113.0110-2.1.0179.0174.0170.0166.0162.0158.0154.0150.0146.0143-2.0.0228.0222.0217.0212.0207.0202.0197.0192.0188.0183-1.9.0287.0281.0274.0268.0262.0256.0250.0244.0239.0233-1.8.0359.0351.0344.0336.0329.0322.0314.0307.0301.0294-1.7.0446.0436.0427.0418.0409.0401.0392.0384.0375.0367-1.6.0548.0537.0526.0516.0505.0495.0485.0475.0465.0455-1.5.0668.0655.0643.0630.0618.0606.0594.0582.0571.0559-1.4.0808.0793.0778.0764.0749.0735.0721.0798.0694.0681表9-8标准正态分布曲线下的面积自-∞到-u的面积Φ(-∞,-u),Φ(u,+∞)=1-Φ(-∞,-u)39\n-1.4.0808.0793.0778.0764.0749.0735.0721.0798.0694.0681-1.3.0968.0951.0934.0918.0901.0885.0869.0853.0838.0823-1.2.1151.1131.1112.1093.1075.1056.1038.1020.1003.0985-1.1.1357.1335.1314.1292.1271.1251.1230.1210.1190.1170-1.0.1587.1562.1539.1515.1492.1469.1446.1423.1401.1379-0.9.1841.1814.1788.1762.1736.1711.1685.1660.1635.1611-0.8.2119.2090.2061.2033.2005.1977.1949.1922.1894.1867-0.7.2420.2339.2358.2327.2296.2266.2236.2206.2177.2148-0.6.2743.2709.2676.3643.2611.2578.2546.2514.2483.2451-0.5.3085.3050.3015.2981.2946.2912.2877.2843.2810.2776-0.4.3446.3409.3372.3336.3300.3264.3228.3192.3156.3121-0.3.3821.3783.3745.3707.3669.3632.3594.3557.3520.3483-0.2.4207.4168.4129.4090.4052.4013.3974.3936.3897.3859-0.1.4602.4562.4522.4483.4443.4404.4364.4325.4286.4247-0.0.5000.4960.4920.4880.4840.4801.4761.4721.4681.4641u.00.01.02.03.04.05.06.07.08.0940