
- 1.43 MB
- 2022-09-01 发布


- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
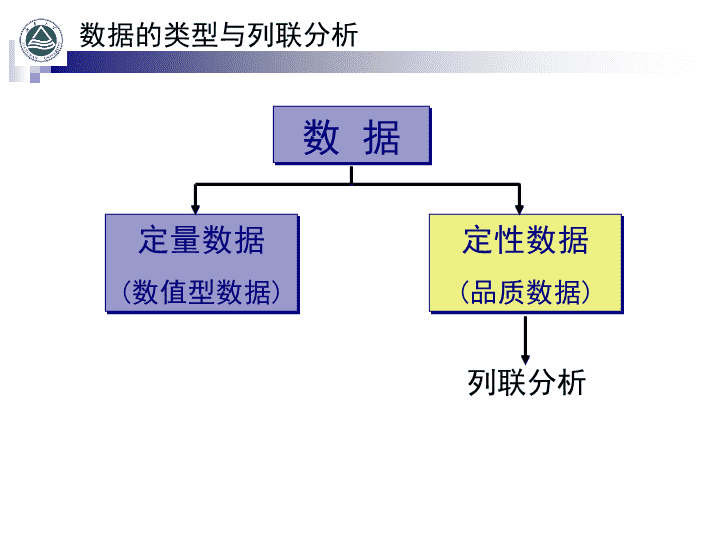
第9章 列联分析9.1分类数据与列联表9.2拟合优度检验9.3独立性检验9.4列联表中的相关测量9.3列联分析中应注意的问题\n数据的类型与列联分析数据定量数据(数值型数据)定性数据(品质数据)列联分析\n9.1分类数据与列联表9.1.1分类数据9.1.2列联表的构造9.1.3列联表的分布\n9.1.1分类数据定类和定序数据都是定性数据,或称分类数据.分类数据表现为类别.例如:性别(男,女)各类别也可用符号或数字代码来表示.例如:1.男;2.女对定类或定序数据的描述和分析通常使用列联表,并采用检验.\n9.1.2列联表(contingencytable)的构造1.由两个或两个以上变量进行交叉分类的频数分布表.2.行变量的类别数用r表示,列变量的类别数用c表示.3.由行变量和列变量的所有可能组合的频数构成的表格,称为列联表.4.一个r行c列的列联表称为r×c列联表.\n2×2列联表列 行12合计12合计表示i行j列的观察频数,行合计列合计.而样本容量\n列 行12…c合计1…2…………………r…合计r×c列联表表示i行j列的观察频数,行合计列合计.而样本容量\n部门态度一分公司二分公司三分公司四分公司合计赞成该方案68755779279反对该方案32453331141合计10012090110420表9-1关于改革方案的调查结果单位:人例一个集团公司在四个不同的区域设有分公司,现该集团公司欲进行一项改革,此项改革可能涉及到各分公司的利益,故采用抽样调查方法,从四个分公司共抽取420名职工,了解职工对此项改革的看法,调查结果见表9-1.\n9.1.3列联表的分布1、观察值的分布边缘分布行边缘分布行观察值的合计数的分布例如,赞成改革方案的共有279人,反对改革方案的141人列边缘分布列观察值的合计数的分布例如,四个分公司接受调查的人数分别为100人,120人,90人,110人条件分布与条件频数变量X条件下变量Y的分布,或在变量Y条件下变量X的分布每个具体的观察值称为条件频数\n观察值的分布(图示)一分公司二分公司三分公司四分公司合计赞成该方案68755779279反对该方案32753331141合计10012090110420行边缘分布列边缘分布条件频数\n2.百分比分布条件频数反映了数据的分布,但不适合对比,为在相同的基数上进行比较,可以计算相应的百分比,称为百分比分布。行百分比:行的每一个观察频数除以相应的行合计数(fij/ri)列百分比:列的每一个观察频数除以相应的列合计数(fij/cj)总百分比:每一个观察值除以观察值的总个数(fij/n)\n表9-2包含百分比的2×4列联表一分公司二分公司三分公司四分公司合计赞成该方案68755779279行百分数%24.4%26.9%20.4%28.3%66.4%列百分数%68.0%62.5%63.35%71.8%—总百分数%16.2%17.8%13.6%18.8%—反对该方案32453331141行百分数%22.7%31.9%23.4%22.0%33.6%列百分数%32.0%37.5%36.7%28.2%—总百分数%7.6%10.7%7.9%7.4%—合计10012090110420%23.8%28.5%21.5%26.2%100%\n3.期望值的分布(1)假定行变量和列变量相互独立(2)实际频数 的期望频数的估计是总频数的个数n乘以该实际频数落入第i行和第j列的概率,即\n计算例根据表9-1,第一行第一列的实际频数 ,相应的期望频数的估计则为类似可求得各个实际频数的期望频数的估计列于表9-4.\n部门态度一分公司二分公司三分公司四分公司合计赞成该方案实际频数68755779279期望频数(66)(80)(60)(73)反对该方案实际频数32453331141期望频数(34)(40)(30)(37)合计10012090110420实际频数和估计的期望频数分布表表9-4如果各个分公司对改革方案的看法相同,观察值和期望值就应当非常接近。\n9.2拟合优度检验9.2.1统计量1.常用于检验列联表中变量之间是否独立的检验,尤其适合于两个定类变量之间是否独立的检验,或多个总体是否有相同的分布.2.统计量为(9.1)3.值愈大则表明实际频数与由确定的期望频数的差异愈大.\n表9-5计算表\n9.2.2拟合优度检验(goodnessoffittest)1.检验多个变量之间是否存在显著差异2.检验的步骤(1)例如提出原假设和备择假设不全相等(3)对规定的显著性水平 ,若则拒绝.否则不能拒绝 ,即接受.(2)计算检验的统计量\n例9.1某集团公司欲进行一项改革,分别从所属的四个分公司中共随机抽取了420名职工,了解他们对改革方案的态度(见表9-1),并对职工态度是否与所在单位有关这个问题在的显著性水平上进行检验.\n解:由(9.1)式得不全相等从而接受 ,即认为四个分公司对改革方案的赞成比例是一致的.由(9.2)式,得自由度.取 时,查表得由于\n例9.2为了提高市场占有率,A公司和B公司同时开展了广告宣传.在广告宣传战之前,A公司的市场占有率为0.45,B公司的市场占有率为0.40,其他公司的市场占有率为0.15.为了了解广告战之后A、B和其他公司的市场占有率是否发生变化,随机抽取了200名消费者.其中102人表示准备购买A公司产品,82人表示准备购买B公司产品,另外16人表示准备购买其他公司产品.检验广告战前后各公司的市场占有率是否发生了变化.(0.05)\n解:当原假设成立时,则原假设中至少有一个不成立由(9.1)式得\n续从而拒绝 ,即认为可以认为广告后各公司产品市场占有率发生显著变化.由(9.2)式,得自由度.取 时,查表得由于\n用Excel计算p值第1步:将观察值输入一列,将期望值输入一列.第2步:选择【插入】菜单.第3步:选择【函数】选项.第4步:先在函数分类中选【统计】,然后在函数名中选【CHITEST】,再点击【确定】.第5步:在对话框【Actualrange】输入观察数据区域,在对话框【Expectedrange】输入期望数据区域,得p值为0.0167114所以拒绝原假设.\n第一步:依次单击“插入”“函数”依次单击“插入”→“函数”\n第二步:依次单击“统计”→“CHITEST”→“确定”\n第三步:先在对话框【Actualrange】输入观察数据区域,然后在对话框【Expectedrange】输入期望数据区域得到p值0.0167114。\n拟合优度检验(例题分析)例某空调系统的区域销售商将该地区划分为四个区域。一个想购买该空调销售权的人被告知这四个区域中的销售情况基本相同。这个期望购买者在该公司的文档记录中随意抽取了40份空调安装记录,结果如表。检验原假设是否成立。(=0.05)\n解:H0:空调安装数在四个区域中是均匀分布的H1:原假设中至少有一个不成立决策:在=0.05的水平上不能拒绝H0结论:可以认为空调安装数在四个区域中是均匀分布的。\n拟合优度检验(练习题)从历史数据可知,创维电视的销售量中,有40%是小屏幕电视(小于21寸),40%是中等屏幕的电视(21—29),还有20%是大屏幕(超过29寸),为了指定下个月适合的生产计划,从现在的购买者中随机抽取了100人的一个样本,发现购买的电视中有55台是小屏幕的,35台是中等屏幕的,还有10台是大屏幕的。在0.01的显著性水平下,检验销售量的历史模式是否成立。\n解:H0:在售出的所有电视中,小、中、大屏幕所占的比例分别为40%、40%、20%H1:比例发生变化所以拒绝H0,即比例发生了变化,小增加,大减少了。\n9.3独立性检验1.检验列联表中的行变量与列变量之间是否独立2.检验的步骤(1)提出原假设和备择假设:行变量与列变量独立:行变量与列变量不独立(2)计算检验统计量(3)对规定的显著性水平 ,若则拒绝.否则不能拒绝 ,即接受.\n独立性检验的出发点如果变量A和变量B相互独立,那么根据概率论中的独立性规则,P(AB)=P(A)P(B),若P(AB)≠P(A)P(B),便说明它们并不相互独立。在独立性假设条件下分别计算出A和B个类别发生的理论概率,并估计相应的频数,最后把观察值与期望值相比较,做出决策。\n例9.3一种原料来自三个不同的地区,原料质量划分成三个不同等级.从这批原料中随机抽取500件进行检验,结果如表9-9所示.要求检验各个地区和原料之间是否存在依赖关系.表9-9原料抽样结果单位:件\n表9-103×3列联表计算过程解::地区和原料之间独立:地区和原料之间不独立\n续取 时,查表得由于所以拒绝 ,接受.即认为地区和原料之间不独立.\n独立性检验(练习题)检验服装店顾客的性别和年龄是否是独立的。=0.05)\n解:H0:服装店顾客的性别和年龄是独立的H1:服装店顾客的性别和年龄是相关变量期望频数分布表所以拒绝H0,服装店顾客的性别和年龄是相关变量\n拟合优度检验与独立性检验的比较1.抽取样本的方法不同:拟合优度检验通常分别各类别各自抽取一个样本,而独立性检验则只抽取一个样本,并在抽样后再分类.2.原假设不同:拟合优度检验通常检验一组样本数据是否服从某一分布,或多组样本数据是否服从同一分布(或具有相同分布).而独立性检验则是检验行变量与列变量是否独立.\n9.4列联表中的相关测量9.4.1相关系数9.4.2列联相关系数9.4.3V相关系数9.4.4数值分析\n品质相关两个变量之间相关程度主要用相关系数表示,列联表中的相关测量,就是利用 值计算相关系数.列联表中的变量通常为定类变量或定序变量,对于定类变量或定序变量之间的相关,称为品质相关.\n一.相关系数1.2×2列联表中数据的相关程度2.系数的绝对值在0-1之间3.相关系数为(9.6)\n表9-11因素因素X合计Yx1x2y1aba+by2Cdc+d合计a+cb+dn=a+b+c+d2×2列联表\n相关系数的计算1.期望频数(估计)为3.相关系数为2.统计量为(9.7)\n相关系数的特例1.当ad=bc,则2.b=0,c=0时,或a=0,d=0列联表中变量的位置可以互换,从而的符号没有实际意义,故取绝对值即可.越大,说明相关程度越高.时,表明变量之间完全相关.\n9.4.2列联相关系数1.大于2×2列联表中数据的相关程度2.列联相关系数(9.8)其中3.C的取值范围为0
-
 关注微信公众号售出明细实时看
关注微信公众号售出明细实时看