

- 5.65 MB
- 2022-09-01 发布


- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
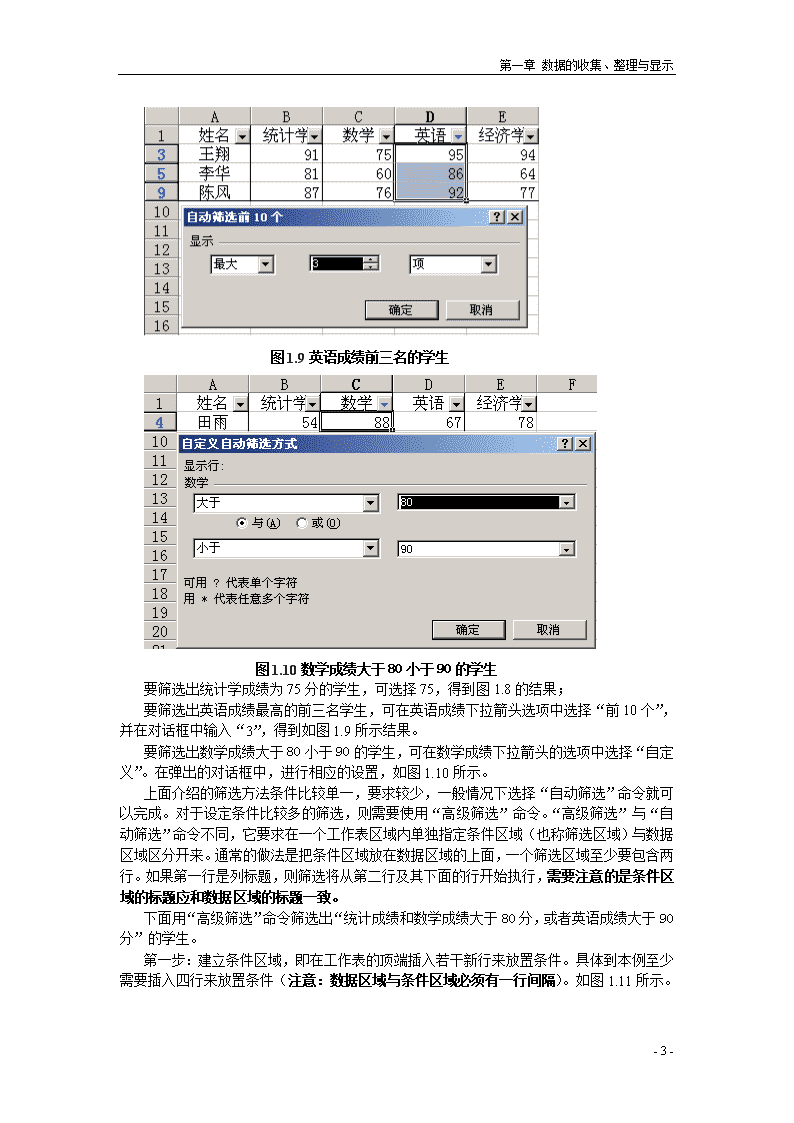
第一章数据的收集、整理与显示数据的收集、整理与显示统计数据的收集、整理与显示是统计分析的基础和初步,其中涉及到抽样方法的选择,数据的筛选、排序,数据的分类和分组以及频数分布的制作等。本章主要介绍如何使用Excel进行相应处理,其中第一节统计数据的收集,介绍“抽样”工具的使用;第二节数据的预处理,介绍“筛选”、“排位和百分比排位”工具的使用;第三节品质数据的整理与显示,介绍如何使用“直方图”工具制作品质型数据的频数分布;第四节数值型数据的整理与显示,介绍如何使用“直方图”工具制作数值型数据的频数分布以及多变量数据的雷达图制作。第一节统计数据的收集数据的处理是数据整理的先前步骤,是在对数据分类或分组之前所做的必要处理,包括数据的审核、筛选、排序等。本节主要介绍Excel中筛选和排序功能的使用。一、数据筛选数据筛选包括两方面内容:一是将某些不符合要求的数据或有明显错误的数据予以剔除;二是将符合某种特定条件的数据筛选出来,对不符合特定条件的数据予以剔除。下面举例说明Excel进行数据筛选的过程。表1-28名学生的考试成绩数据单位:分表1-2是八名学生四门课程的考试成绩数据,使用Excel“筛选”命令分别找出统计成绩等于75分的学生;英语成绩前三名的学生;数学成绩大于80小于90的学生;统计成绩和数学成绩大于80分,或者英语成绩大于90分的学生。Excel提供了两种筛选命令:“自动筛选”(适用于简单的条件)和“高级筛选”(适用于复杂的条件)。接下先来介绍“自动筛选”的使用。首先,将表格中的数据区域选定或者只需确保活动单元格处于数据区域既可(如表1-2所示,活动单元格为B3)。选择“数据”菜单,并选择“自动筛选”命令。如图1.6所示。-21-\n第一章数据的收集、整理与显示图1.6从“数据”菜单中选择“筛选自动”这时会在第一行(列标题)出现下拉箭头,用鼠标点击箭头会出现如下结果,如图1.7所示。图1.7“自动筛选”命令图1.8统计成绩75分的学生-21-\n第一章数据的收集、整理与显示图1.9英语成绩前三名的学生图1.10数学成绩大于80小于90的学生要筛选出统计学成绩为75分的学生,可选择75,得到图1.8的结果;要筛选出英语成绩最高的前三名学生,可在英语成绩下拉箭头选项中选择“前10个”,并在对话框中输入“3”,得到如图1.9所示结果。要筛选出数学成绩大于80小于90的学生,可在数学成绩下拉箭头的选项中选择“自定义”。在弹出的对话框中,进行相应的设置,如图1.10所示。上面介绍的筛选方法条件比较单一,要求较少,一般情况下选择“自动筛选”命令就可以完成。对于设定条件比较多的筛选,则需要使用“高级筛选”命令。“高级筛选”与“自动筛选”命令不同,它要求在一个工作表区域内单独指定条件区域(也称筛选区域)与数据区域区分开来。通常的做法是把条件区域放在数据区域的上面,一个筛选区域至少要包含两行。如果第一行是列标题,则筛选将从第二行及其下面的行开始执行,需要注意的是条件区域的标题应和数据区域的标题一致。下面用“高级筛选”命令筛选出“统计成绩和数学成绩大于80分,或者英语成绩大于90分”的学生。第一步:建立条件区域,即在工作表的顶端插入若干新行来放置条件。具体到本例至少需要插入四行来放置条件(注意:数据区域与条件区域必须有一行间隔)。如图1.11所示。-21-\n第一章数据的收集、整理与显示图1.11条件区域的建立图1.12“高级筛选”命令的使用Excel将根据以下规则解释这一区域:◆同一行中的条件之间的关系是“与”。◆不同行中的条件之间的关系是“或”。第二步:选择“高级筛选”命令,在弹出的对话框中进行相应的设置。如图1.12所示。在本例在“数据区域(L)”输入A5:E13,在“条件区域(C)”输入A1:C3,回车确定即可。结果见表1-3。需要说明的是“自动筛选”和“高级筛选”命令显示筛选出的数据时,Excel仅仅把不符合要求的行隐藏起来,并且为了提醒用户此区域是经过筛选的数据区域,Excel会用对比颜色来显示筛选出的行数。如果要取消“筛选”,可以单击“筛选”菜单上的“全部显示”命令,也可以单击下拉列表框并选择“全部”(此时使用的是“自动筛选”命令)。所以,为了保证筛选结果的正确与“安全”,通常需要把每一次筛选的结果复制到其它工作表中。表1-3筛选结果-21-\n第一章数据的收集、整理与显示二、数据的排序数据排序是按一定的顺序将数据排列,以便研究者通过排序后数据的特征或趋势,找出解决问题的线索。对于数值型数据的排序,即递增和递减排序,在Excel“数据”菜单中的“排序”命令可以很方便的实现这一功能,由于篇幅所限这里不再介绍。下面介绍如何利用Excel的“排位和百分比排位”分析工具来进行分析,此工具可以产生次序排位和百分比排位。以表1-2为例,步骤如下:第一步:在“工具”下拉菜单中单击“数据分析”选项,从其对话框“分析工具”列表中选择“排位和百分比排位”,回车打开其对话框(见图1.13,图1.14)。图1.13“排位和百分比排位”命令图1.14“排位和百分比排位”命令对话框-21-\n第一章数据的收集、整理与显示第二步:(以统计学成绩单列数据为例)对命令对话框进行相应设置。本例统计学成绩数据区域为“B1:B9”,“输入区域(I)”输入“B1:B9”。“分组方式”要求指出输入区域中的数据是按行还是按列排列,在本例中选择默认设置“列”。如果“输入区域(I)”的第一行包含了标志项,则需单击选中“标志位于第一行(L)”复选框,本例显然要选中此项。在输出选项中,按照需要相应选择,本例因输出结果比较多,所以选择“新工作表组(P)”。设置完毕,回车确定,结果见表1-4。表1-4排位和百分比排位结果显示结果包括四列:第一列“点”为数据原来的排列顺序;后三列依次为数据值、数据值排序和百分比排序。百分比排序的数值指的是“好于多少的”数据,如统计学成绩87分的百分比排序值为85.7%,指的是其成绩好于85.7%的其它数据。在本例中,使用“排位和百分比排位”分析工具分析了统计学单列数据。可以使用此工具分析全部四个成绩:统计学、数学、英语、经济学,在这种情况下应指定“B1:E9”为输入区域,工具将输出16列数据。第三节品质数据的整理与显示数据经过预处理后,可进一步做分类或分组整理。在对数据进行整理与显示时,首先要弄清是什么类型的数据,不同类型的数据适用的处理方法不同。一般情况下,对品质数据主要是分类整理,对数值型数据主要是分组整理。本节以及下一节(数值型数据的整理与显示)主要介绍这两大类数据频数分布的制作,而对于一般图形的制作,如:条形图、饼行图、直方图、圆环图等属于Excel的基本内容,由于篇幅所限不在这里讲述。下面通过一个具体的例子来说明如何使用Excel来制作定类数据的频数分布。表1-5是一家市场调查公司为研究不同品牌饮料的市场占有率,调查员某天对50名顾客购买饮料品牌记录的原始数据。具体做法是:如果一个顾客购买某一品牌的饮料,就将这一饮料的品牌记录一次。表1-5顾客购买饮料品牌的记录-21-\n第一章数据的收集、整理与显示因为Excel无法识别非数值型数据,所以为了用Excel建立饮料品牌的频数分布,首先需要将字符数字化。为此,通常的做法是将不同品牌的饮料用一个数字代码来表示。本例对各种品牌饮料指定的代码是:1.可口可乐2.旭日升冰茶3.百事可乐4.汇源果汁5.露露然后,将各品牌的代码输入到Excel工作表中。假定这里已将品牌代码输入到Excel工作表中的B2:B51,这样就将定类数据转化为数值型数据。为建立频数分布表和条形图,Excel还要求将每个品牌的代码作为分类标志单独输入到任何一列,这里将代码输入到工作表的C4:C8(见表1-6)。这样,Excel就可以对数值小于或等于每一品牌代码的数据进行计算,提供的合计数就是各品牌的频数分布。下面是用Excel产生频数分布表和图形的步骤:第一步:在“工具”下拉菜单中单击“数据分析”选项,从其对话框“分析工具”列表中选择“直方图”,回车打开其对话框(如图1.15,图1.16所示)。图1.15从对话框“分析工具”列表中选择“直方图”-21-\n第一章数据的收集、整理与显示图1.16对话框的设置第二步:对命令对话框进行相应设置。本例“输入区域(I)”为B2:B51(请注意:是转换后代码的区域,而不是A2:A51字符的区域);“接受区域(B)”为C4:C8,即分类标志的区域(注意:“接受区域(B)”不能为空且内容必须正确,即为分类标志。只有这样Excel才能识别任务,程序可以统计出数字“1”、“2”等分类标志的个数,即每一类别的个数;还可以统计出小于等于数字“2”、“3”、“4”、“5”的个数,从而达到统计累积频率的目的)。在输出选项中可根据自己的需要确定,本例选择“输出区域(O)”并键入E1(意思是结果从本工作表E1位置开始输出结果)。选择“累积百分率(M)”(若不需要时,此项可不选)和“图表输出(C)”,然后回车确定,结果见表1-6。表1-6频数分布结果-21-\n第一章数据的收集、整理与显示为了把输出结果转化为易读的形式,应将结果进一步修改和修饰。这里可以将频数分布表中的“接收”用描述性标题“饮料品牌”来代替,将“频率”改为“频数”(输出结果的频率实际上频数),将品牌的代码1,2,3,4,5用相应品牌的名称可口可乐、旭日升冰茶、百事可乐、汇源果汁、露露来代替。并将“其他”行(Excel的一个固定输出形式)去掉,换以相应的“合计”内容,结果见表1-7(这里提醒读者的是,因为表1-6输出结果中,频数分布表和频数分布图为一个相关联的整体,所以当对频数分布表进行修改时,分布图也会相应的变化。如:将品牌的代码1,2,3,4,5用相应品牌的名称代替后,分布图中的分组标志也相应的变成品牌名称)。表1-7不同品牌饮料的频数分布对于频数分布图,可以自己设计,如图形的背景、颜色、字体、坐标的刻度等。Excel可以很容易地绘制出漂亮的图形。需要注意的是,初学者往往会在图形的修饰上花费太多的时间和精力,这样做得不偿失,也未必合理,或许会画蛇添足。图形的绘制应尽可能的简洁,以能够清晰地显示数据、合理地表达统计目的为依据。第四节数值型数据的整理与显示上一节介绍了品质数据频数分布的制作,本节将介绍一些统计中常用到的数值型数据的整理与显示方法。一、数值型数据的分组与图示数值型数据包括定距和定比数据,在整理时通常要进行数据分组,就是根据统计研究的需要,将数据按某种标准化分成不同的组别。分组后再计算出各组中出现的次数和频数,就形成了一张频数分布表。下面结合具体的例子来说明,表1-8是某生产车间50名工人日加工零件数(单位:个),采用等距分组的形式制作频数分布表和分布图。在使用Excel前,首先需要明确分几组,组距以及每组的上下组限。一般情况下,可以按Sturges公式来确定组数K:K=1+其中,n为数据的个数,对结果用四舍五入的办法取整即为组数。组距是一个组的上限和下限的差,可根据全部数据的最大值和最小值及所分的组数来确定,即组距=(最大值—最小值)÷组数。本例假定根据上述方法分为五组,组距为10:100-110;110-120;120-130;130-140;140-150。表1-8生产车间50名工人加工零件数-21-\n第一章数据的收集、整理与显示与品质数据一样,使用“数据分析”中的“直方图”工具来制作频数分布。首先,需要给定数据的“输入区域”和“接受区域”。这里的“接受区域”相应的变为分组标志,但是由于Excel不能识别非数值型字符,所以不能把100-110,110-120,120-130,130-140,140-150输入一列作为“接受区域”,程序规定只能把上组限值作为分组标志,即110,120,130,140,150。需要强调的是在制作频数分布的时候,由于相邻两组的上下组限重叠,为了避免重复,通常采用“上组限不在内”的原则。由于Excel无法识别这一原则,但为了与通常的做法相一致,需要将上组限都减去1,即分组标志变为:109,119,129,139,149。假定已将样本数据和分组标志输入到相应的位置(如表1-9所示),步骤同第三节品质数据的频数分布制作相同(这里做简单介绍)。表1-9生产车间50名工人加工零件数和分组标志单位:个第一步:在“工具”下拉菜单中单击“数据分析”选项,从其对话框“分析工具”列表中选择“直方图”,回车打开其对话框。第二步:在“直方图”对话框的“输入区域(I)”输入A1:A51,“接受区域(B)”输入C2:C7,这时还需要单击选定“标志(L)”复选框(请读者自己思考为什么?)。第三步:在输出选项中,本例在“输出区域(O)”中键入D1,同时单击“累积百分率(M)”和“图表输出(C)”复选框。回车确定即可,结果输出见表1-10。-21-\n第一章数据的收集、整理与显示表1-10频数分布输出结果同样,为了把输出结果转化为易读的形式,应进一步修改表格和修饰图形。如下表1-11所示,把分组标志转换为标准、易懂的形式。同时,如上节所述,分布图的标志随着频数分布表的修改相应变化(读者可自己验证)。表1-11日产零件的频数分布-21-\n第一章数据的收集、整理与显示数据分布特征的测度对数据分布特征主要从三个方面进行测度和描述:一是分布的集中趋势,反映数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏斜程度和峰度。本章主要介绍如何使用函数以及“数据分析”工具对数据分布特征进行测度和描述。第一节函数的介绍本节主要介绍在统计分析中需要用到的一些函数,其中包括我们本章(描述统计)中以及在概率分布、参数估计与假设检验、方差分析、相关与回归等分析中涉及到的函数,读者在后面章节的学习中可以参阅本节的内容。一、统计计算中经常用到的函数(函数列表)★本小节摘自:安维默主编,《统计电算化》第34~37页,中国统计出版社,2000Excel为用户提供了数学、三角函数、统计函数、数据库函数、财务函数、工程函数、逻辑函数、文本函数、时间和日期函数、信息函数、查找和引用函数等10类300多种,可以满足多方面的需要。其中,统计函数最多达78种;此外还有14种数据库函数,以及在统计中经常使用的数学函数20种,合计112种。下面将这些函数名称及功能列表显示。表2-1可用于统计分析的函数函数名称函数功能介绍一、统计函数1、用于数据整理的函数FREQUENCY2、用于描述统计的函数MODEMEDIANAVERAGEAVERAGEAHARMEANGEOMEANTRIMMEANMAXMAXAMINMINALARGESMALLQUARTILEAVEDEVDEVSQ求分组数据的频数求一组数据的众数求一组数据的中位数求一组数据的均值求数据清单中数据的均值求调和平均数求几何平均数求去掉最大值和最小值的平均数求一组数据中的最大值求数据清单中包含逻辑值和字符串的最大值求一组数据中的最小值求数据清单中包含逻辑值和字符串的最小值求一组数据中第K个最大值求一组数据中第K个最小值求一组数据中的四分位数求样本数据与其均值的平均离差求样本数据与其均值离差的平方和-21-\n第一章数据的收集、整理与显示STDEVSTDEVASTDEVP求样本标准差求包含逻辑值和字符串的样本标准差求总体标准差表2-1可用于统计分析的函数(续1)函数名称函数功能介绍STDEVPAVARVARAVARPVARPAKURTSKEW1、用于概率分布的函数BINOMDISTNEGBINOMDISTCRITBINOMPISSONNORMDISTNORMINVNORMSDISTNORMSINVSTANDARDIZELOGNORMDISTLOGINVHYPGEOMDISTBETADISTBETAINVGAMMADISTGAMMAINVGAMMALNEXPONDISTWEIBULLPROBPERMUT2、用于区间估计的函数CONFIDENCE3、用于假设检验的函数CHIDISTCHIINVCHITESTZTESTTDISTTINVTTEST求包含逻辑值和字符串的总体标准差求样本方差求包含逻辑值和字符串的样本方差求总体方差求包含逻辑值和字符串的总体方差求一组数据的峰度求一组数据的偏度求二项分布的概率求负二项分布的函数值求累积二项分布大于或等于临界值的最小值求泊松分布的概率求非标准正态分布的累积函数求非标准正态分布累积函数的逆函数求标准正态分布的累积函数求标准正态分布累积函数的逆函数求Z分布的正态化数值求对数正态分布的累积函数求对数正态分布累积函数的逆函数求超几何分布的概率求分布的累积函数求分布累积函数的逆函数求分布的累积函数求分布累积函数的逆函数求分布累积函数的自然对数求指数分布求韦伯分布求指定区域内事件对应概率之和求从数据集合中选取若干对象的排列数求总体均值的置信区间求分布的单尾概率求分布单尾概率的逆函数求分布的统计量和相应的自由度求Z检验的双尾概率求t分布求t分布的逆函数求t检验的概率值-21-\n第一章数据的收集、整理与显示FDISTFINVFTEST求F分布求F分布的逆函数求F检验的单尾概率表2-1可用于统计分析的函数(续2)函数名称函数功能介绍1、用于方差分析的函数COVRB2、用于相关和回归的函数CORRELPEARSONRSQFISHERFISHERIVELINESTINTERCEPTSLOPEFORECASTTRENDSTEYXLOGESTGROWTH3、其他统计函数COUNTCOUNTARANKPERCENTRANKPERCENTILE二、数据库函数DCOUNTDCOUNTADGETSUBTOTALDSUMDPRODUCTDAVERAGEDMAXDMINDSTDEVDSTDEVPDVARDVARPSOLREQUEST三、统计中常用的数学函数求协方差求相关系数求皮尔逊乘积矩相关系数求皮尔逊乘积矩相关系数的平方求费雪变换值(用于相关系数的假设检验)求费雪变换的逆函数建立直线方程求直线方程的截距求直线方程的斜率求线性趋势值(预测值)求线性趋势值(预测值)求趋势值的标准误差建立指数曲线方程求指数曲线趋势值(预测值)求数组中数据的个数(只计算数字型数据)求数组中数据的个数(包含逻辑值、文本值等)求某一数值在一组数据中的排位求某一数值在一组数据中的百分比排位求数组的K百分比数值点计算数据库中符合指定条件并含有数字的单元格数计算数据库中符合指定条件的非空单元格数从数据库中抽取一个符合指定条件的记录将数据清单、数据序列和数据库中的数据分类汇总计算数据库中符合指定条件的记录字段数值之和计算数据库中符合指定条件的记录字段数值的乘积计算数据库中指定项目的平均数从数据库指定项目中求最大值从数据库指定项目中求最小值从数据库中指定项目求样本标准差从数据库中指定项目求总体标准差从数据库中指定项目求样本方差从数据库中指定项目求总体方差链接外部数据,从中查找数据,以数组形式求结果-21-\n第一章数据的收集、整理与显示SUMSUMIFPRODUCTQUOTIENT对一组数据求和将符合条件的数据求和参数相乘求两数相除的整数部分表2-1可用于统计分析的函数(续3)函数名称函数功能介绍MODPOWERSQRTRANDRANDBETWEENCOMBINCOUNTIFFACTLNLOGLOG10SUMPRODUCTSUMSQSUMXMY2SUMX2MYSSUMX2PY2求两数相除的余数求数值的乘幂求数值的平方根求0~1之间的随机数求指定两数之间的随机数求指定对象数目的组合数求符合指定条件区域的非空单元格数求某数的阶乘求某数的自然对数求某数以指定底数为底的对数求某数以10为底的对数求两组对应元素乘积之和求参数的平方和求两数组对应值之差的平方和求两数组对应值平方差之和求两数组对应值平方和之和二、函数的使用1、函数的语法工作表函数包括两个部分:函数名和紧跟的一个或多个参数。函数名,例如SUM和AVERAGE,表明函数要执行的操作;参数则指定函数所使用的值或单元格。例如,在公式“=SUM(C3:C5)”中,SUM为函数名,C3:C5为参数。此函数计算单元格C3、C4和C5中值的总和。函数的参数可以为数值类型。例如,公式“=SUM(327,209,176)”中的SUM函数将数字327、209和176求和。不过通常的做法是,先在工作表的单元格中输入使用的数字,然后将这些单元格作为函数的参数使用。请注意函数参数两端的括号:开括号表示参数的开始,必须紧跟在函数名后。如果在函数名和括号之间输入了空格或其他字符,那么Excel会显示错误信息“MicrosoftExcel在公式中发现了错误。建议更正如下:是否接受建议的修改?”如果单击【是】按钮,则Excel会自动更新公式;如果单击【否】按钮,则单元格中将显示错误值。如果在函数中使用多个参数,则要用逗号将参数隔开。例如,公式“=PRODUCT(C1,C2,C5)”告诉Excel将单元格C1,C2,和C5的数值相乘。函数中可使用的参数多达30个,但公式的长度不能超过1024个字符。参数可以是工作表中包括任意数目单元格的区域。例如,函数“=SUM(A1:A5,C2:C10,D3:D7)”-21-\n第一章数据的收集、整理与显示只有3个参数,但对29个单元格的数据进行求和运算(第一个参数A1:A5,指从A1到A5的所有单元格,依此类推)。反过来,引用的单元格中也可以包括公式,这些公式引用更多的单元格或单元格区域。使用这些参数,就可以轻松地创建复杂的公式来执行功能强大的各种操作。2、函数的输入对一些单变量和比较简单的函数,可用键盘直接输入。其方法与在单元格中输入公式相同,首先输入一个“=”号,然后将函数的正确形式输入即可。例如:“=SUM(B2:B5)”等。对于一些复杂或参数较多的函数,其形式难以记忆,可用“粘贴函数”对话框。其步骤如下:第一步:选中某个单元格并选择“插入”菜单中的“函数”命令,或者单击“常用”工具栏上的“粘贴函数”按钮,来显示对话框(见图2.1)。第二步:从对话框左侧的“函数分类”列表中选择所需要的函数类别(表中除前述10类函数外,还有“常用”和“全部”两项);从对话框右侧的“函数名”列表中选择所需要的函数,单击确定或回车确认,屏幕上出现该函数的对话框。本例从“统计”函数分类中,选择AVERAGE(平均数函数),如图2.2所示。图2.1粘贴函数对话框图2.2AVERAGE函数对话框图2.2AVERAGE函数对话框包括两个参数,即等价于公式“=AVERAGE(A1:A5,C2:C5)”-21-\n第一章数据的收集、整理与显示,对9个单元格的数据进行求平均数。在此对话框中,所选函数的每个参数均有相应的编辑框。如果函数参数较多,对话框会在输入可选参数时自动进行扩展。对话框底部会显示对编辑框中当前所包含插入符的参数描述。每个参数编辑框右边的显示区域将显示参数的当前值。对话框底部会显示函数的当前值,如本例计算结果为8。需要说明的是参数多少的选择要根据情况而定,本例使用了两个参数(A1:A5,C2:C5),原因是这两个数据区域不相连,如果将这两组数据放在一列,则只需一个参数。当然,由于不同的函数功能不同,所以在使用中参数的形式可能也不同,这里就不逐一列举。读者在具体的使用中也可以借助Excel的帮助功能。第二节数据分布特征测度函数的使用本节就描述统计中对数据分布特征的测度,所用到的函数做具体的说明。本节以某电脑公司2002年前4个月各天的销售量数据(单位:台)为例,见表2-2。表2-2某电脑公司2002年前4个月各天的销售量一、集中趋势的测度集中趋势的测度值有:众数、中位数、简单均值、调和平均数与几何平均数。在Excel中用函数求这些测度值,可以打开函数的对话框操作,也可以直接输入包含函数的公式。1、众数众数是一组数据中出现次数最多的变量值,用M0表示。具体做法如前所述:选中某个单元格并选择“插入”菜单中的“函数”命令,或者单击“常用”工具栏上的“粘贴函数”按钮,从弹出的对话框左侧“函数分类”列表中选择“统计”,从右侧“函数名”列表中选择MODE函数,回车进入MODE函数对话框(如图2.3所示)。-21-\n第一章数据的收集、整理与显示图2.3MODE函数对话框在对话框的“Number1”框中输入原始数据所在的单元格区域,本例为A1:J12;完成以上操作后在对话框底部给出计算结果,本例为172(台);单击“确定”按钮,计算结果自动计入指定位置。如采取直接输入带函数的公式计算,可单击任一空单元格,输入“=MODE(A1:J12)”回车确认,可得出同样的结果。2、中位数中位数是一组数据排序后,处于中间位置上的变量值,用Me表示。采取直接输入带函数的公式计算,单击任一单元格,输入“=MEDIAN(A1:J12)”,回车确认,即得出结果182(台)。3、均值(1)简单均值对于简单均值,单击任一空格,输入“=AVERAGE(A1:J12)”,回车确认,即可得出结果184.56。(2)调和平均数各变量值倒数的平均倒数,称为调和平均数,用Hm表示。在Excel中,调和平均数也可以用函数求得,但只适用于简单的计算。例如:有甲、乙、丙三种蔬菜,每种蔬菜的价格分别为每斤0.5、0.8和0.9元,现在各买1元钱的每种蔬菜,计算平均价格,就是一个求调和平均数的问题。用求调和平均数函数HARMEAN计算,单击任一单元格,输入“=HARMEAN(0.5,0.8,0.9)”,回车确认,结果为0.688(元)。(3)几何平均数n个变量值乘积的n次方根,称为几何平均数,用Gm表示。几何平均数的计算公式为:Gm=式中,∏为连乘符号。几何平均数是适用于特殊数据的一种平均数,它主要用于计算比率的平均。当我们所掌握的变量值本身是比率的形式,这时就应采用几何平均数计算平均比率。在实际应用中,几何平均数主要用于计算社会经济现象的年平均增长率。例:某水泥生产企业1999年的水泥产量为100万吨,2000年与1999年相比增长率为9%,2001年与2000年相比增长率为16%,2002年与2001年相比为20%。求各年的平均增长率。在Excel中求几何平均数,非常简单,单击任一单元格,输入“=GEOMEAN(0.09,0.16,0.20)”,回车确认,其结果为14.2%。-21-\n第一章数据的收集、整理与显示二、离散程度的测度离散程度的测度值主要有:异众比率、极值、四分位差、标准差、方差。这里就数值型数据离散程度的函数测度做简单介绍。1、极值在Excel中求极值可用MAX和MIN函数求最大值和最小值,然后求其差值。单击任一单元格,输入“=MAX(A1:J12)-MIN(A1:J12)”,即得出其值为96。2、四分位差上四分位数与下四分位数之差,称为四分位差,也称为内距或四分间距,用表示。四分位差的计算公式为:其中,表示上四分位数,表示下四分位数。四分位差反映了中间50%数据的离散程度,其值越小,说明中间的数据越集中;数值越大,说明中间的数据越分散。四分位差不受极值的影响,一定程度反映了中位数对一组数据的代表程度。在Excel中求四分位差,可用QUARTILE函数。按前面所述的步骤,打开QUARTILE函数对话框,如图2.4所示。图2.4QUARTILE函数对话框其中,“Array”框要求输入数据所在的区域,“Quart”框决定返回那一个四分位值。Quart的取值范围为[0,4],具体来讲:◆值为0,表示最小值;◆值为1,下四分位数;◆值为2,中位数;◆值为3,上四分位数;◆值为4,最大值◆值不为整数,将被截尾取整。所以,要计算四分位差,可分别在Quart对话框中输入3、1,然后将返回的上、下四分位数作差。本例也可以单击任一单元格,输入“=QUARTILE(A1:J12,3)-QUARTILE(A1:J12,1)”,即可得到结果为43.25(台)。3、标准差和方差方差和标准差是数值型数据测度离散程度的最主要测度值。各变量值与其均值离差平方和的平均数,称为方差。方差的平方根,称为标准差。通常情况下,总体方差用表示,函数形式为VARP;总体标准差用表示,其函数形式为STDEVP;样本方差用S2-21-\n第一章数据的收集、整理与显示表示,函数形式为VAR;样本标准差用S表示,其函数形式为STDEV。本例如果要求样本方差和样本标准差,可单击单元格在其中输入“=VAR(A1:J12)”或输入“=STDEV(A1:J12)”,即可得到样本方差或样本标准差,分别为470.05,21.68(台)(注意标准差有量纲)。三、偏态与峰态的测度集中趋势和离散程度是数据分布的两个重要特征,但要全面了解数据分布的特点,还需要知道数据分布的形状是否对称、偏斜的程度以及分布的扁平程度等。偏态和峰态就是对分布形状的测度。“偏态”一词是由统计学家Pearson于1895年首次提出的,是对数据分布对称性的测度,其测度值称为偏态系数(SK),测度函数为SKEW。如果一组数据的分布是对称的,则偏态系数等于零;偏态系数大于零,为右偏分布;偏态系数小于零,为左偏分布。本例在任一单元格输入“=SKEW(A1:J12)”,可得到偏态系数为0.41,为右偏分布。“峰态”一词是由统计学家Pearson于1905年提出的,是对数据分布平峰和尖峰程度的测度,其测度值称为峰态系数(K),测度函数为KURT。峰态系数是通过与标准正态分布的峰态系数比较而言的。由于标准正态分布的峰态系数为0,当K>0时为尖峰分布;当K<0时为扁平分布。需要注意的是,有的教课书中其峰态系数计算公式没有减3,所以把标准正态分布的峰态系数作为3,当K>3时为尖峰分布;K<3时为扁平分布。在Excel计算过程中,以零为比较对象。本例在任一单元格输入“=KURT(A1:J12)”可得到峰态系数为-0.22,为扁平分布。第三节描述统计工具的使用上面介绍了数据分布特征的各种函数测度值,其中多数可以通过Excel“数据分析”选项中的“描述统计”命令得出计算结果。仍以表2-2为例,其步骤如下:一、将数据输入到A1:A120区域中,在“工具”下拉菜单中单击“数据分析”选项,从其对话框“分析工具”列表中选择“描述统计”,回车进入“描述统计”对话框。如图2.5所示。-21-\n第一章数据的收集、整理与显示图2.5“描述统计”对话框二、在“输入区域(I)”框中输入“A1:A120”,如果需要指出输入区域的数据是按行或按列排列的,可在“分组方式”后面单击“逐行”或“逐列”选项。选择“逐列”后,如果第一行为标题行,则要单击“标志位于第一行(L)”的复选框。在输出选项中,本例选择“输出区域(O)”,输入“C2”;选择“汇总统计(S)”,可给出一系列描述统计测度值;选择“第K个大值(A)”或“第K个小值(M)”,其右侧框中将显示默认值“1”,即要求给出数据中第1个最大值或最小值。如输入“2”,则要求给出数据中2个最大值或最小值;选择“平均数置信度(N)”是指用样本平均数估计总体平均数的可信程度。如选择此复选框,则其右侧框中将显示默认值95%,如认为不合适,可自己调整。以上各项选定后,回车确认,即可在指定输出区域得到描述统计各测度值的结果,见表2-3。表2-3“描述统计”输出结果最后对表2-3的输出结果做部分解释:◆“平均”指样本均值。◆“标准误差”指样本平均数的“抽样误差”,即样本标准差除以样本单位数的均方。◆“中值”即中位数。◆“模式”即众数。◆“标准偏差”即样本标准差。“区域”即极差,最大值减最小值-21-